Diagrams and workflows as a Code with Agents
Tl;DR
I Got the social signin working here, with the slidev-editor.
+++ Tech Talk about the MermaidxOpenAI PoC
Now its time to bring the AI part to the equation.
If you are an architect, you will like this.
Intro
Same as we can do presentations as a code, we can know diagrams as a code.
In fact, the diagrams as a code (Mermaid) can be integrated with our SliDev-Editor Setup.
I want to create a NextJS web app that will allow for the user to provide an API key via env variable, and it will have a qna chat interface similar to this wireframe.
The focus of the web app will be to create mermaidJS diagram code, based on the user input, that will be editable into a toastUI md editor and changes will be re rendered live
can we make the model be a parameter passed via env
and also make the UI look more modern
#clarify with a prd.md
##create a implementation plan.md with well define phases that can be tested and build one on top of the next phaseDont forget about the tab icon and the opengraph as a requirement when vibe coding webapps!
If you are curious, this was the wireframe:
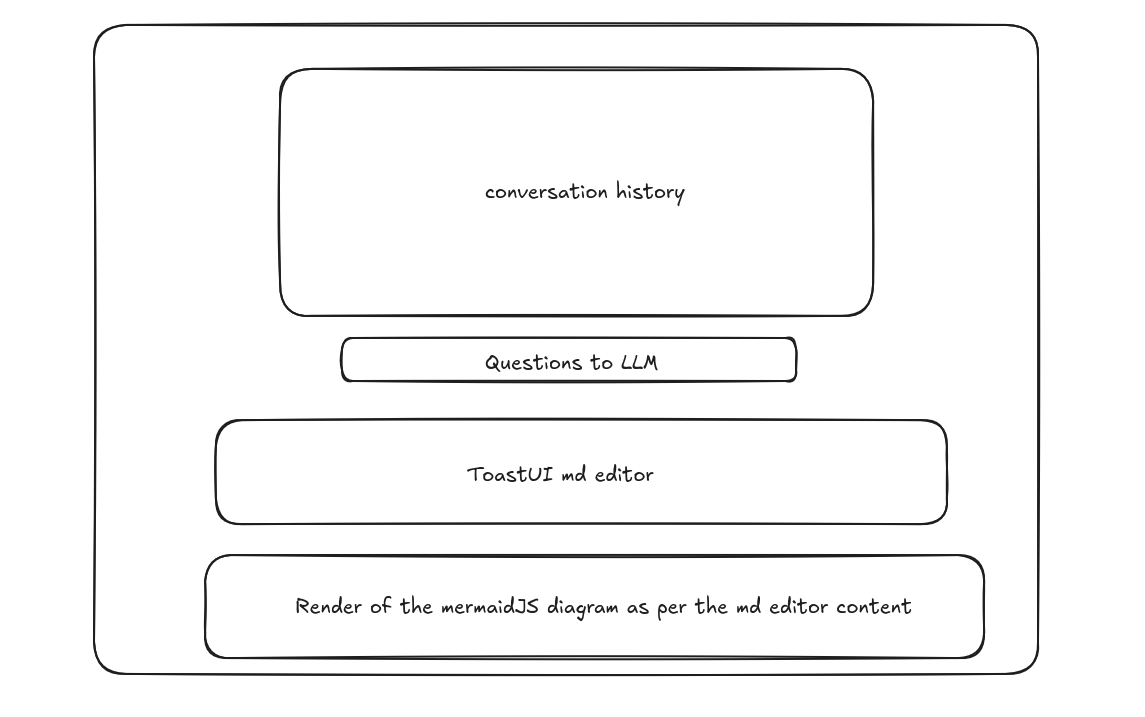
A PRD and implementation plan is always a good idea to vibe code:
#git init && git add . && git commit -m "Initial commit: Starting simple mermaidjs x openai nextjs"- tailwind.config.ts
- Makefile
- README.md
- .env.local
- layout.tsx
- page.tsx
- route.ts
- ChatPanel.tsx
- EditorPanel.tsx
- DiagramPanel.tsx
- system.md
- user.md
After vibe coding 30 min, this is the result: https://mermaid.js.org/config/configuration.html
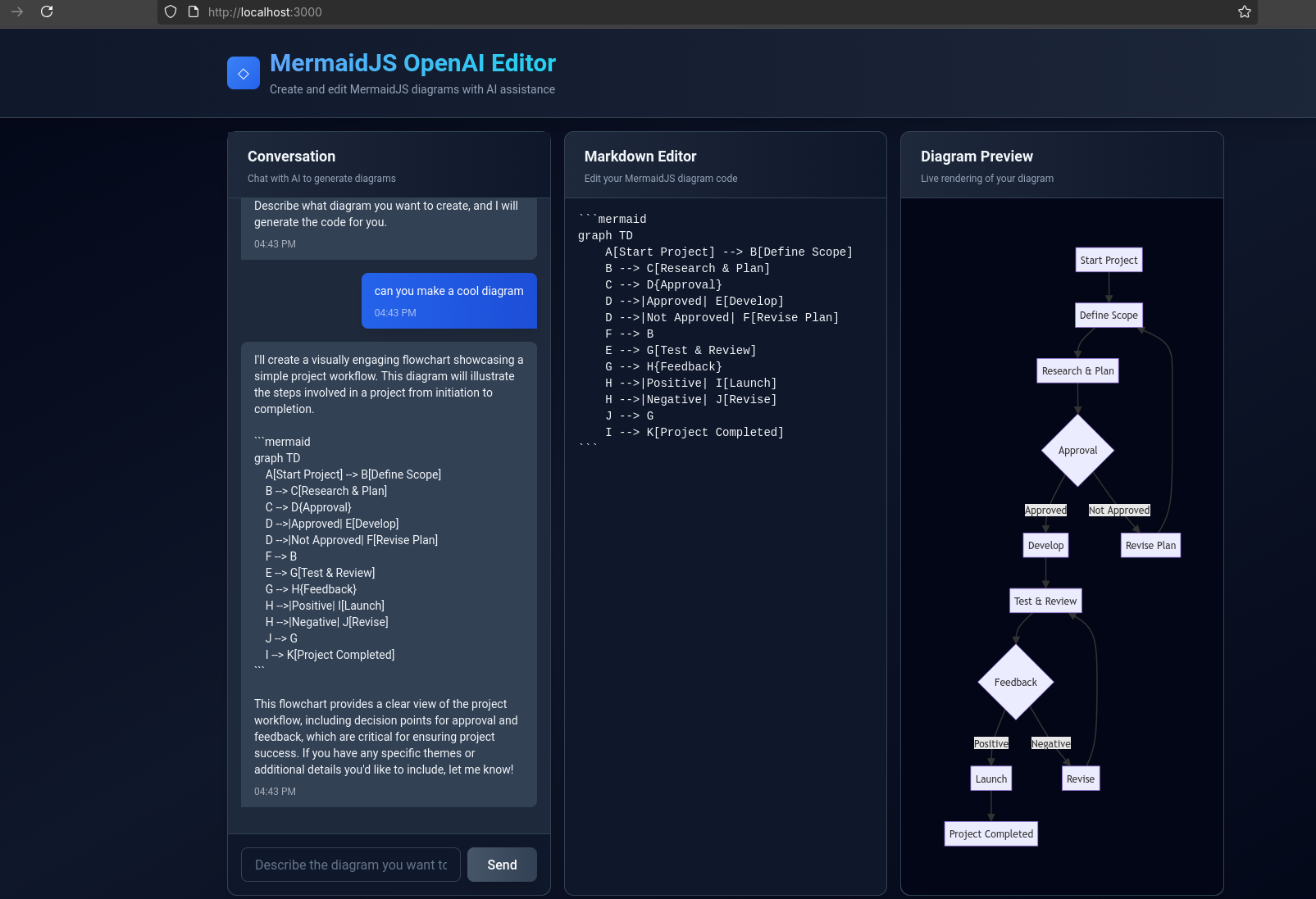
Thanks to Claude Haiku 4.5, I have seen a better way for the docker-compose and their environments:
With a full example here and here
version: '3.8'
services:
app:
build:
context: .
dockerfile: Dockerfile
container_name: mermaidjs-openai-editor
ports:
- "3000:3000"
environment:
- NODE_ENV=production
- OPENAI_API_KEY=${OPENAI_API_KEY}
- LLM_MODEL=${LLM_MODEL:-gpt-4o-mini}
- SYSTEM_PROMPT_PATH=${SYSTEM_PROMPT_PATH:-./prompts/system.md}
- USER_PROMPT_PATH=${USER_PROMPT_PATH:-./prompts/user.md}
- CONVERSATION_HISTORY_LIMIT=${CONVERSATION_HISTORY_LIMIT:-10}It will read from the
.envvariables and if not provided, the default values will kick in:
make help
#docker builder prune -a -f#
make docker-up
#du -sh ~/Desktop/mermaidjsxopenai-editor #~180mb
#docker images | grep mermaidjs #~1.5gbLive info for your PPTs
For live info, you can always try scrapping or this programmatic search engine search.
But if you have tried already, you will know that there might be some complications depending on how the websites are created.
But I got recently 1y trial of Perplexity and its quite cool
And if you are windows/mac user, you can try their Commet browser, with cool web summarization
Anyways, we saw how to bring API data directly to our slides via SliDevJS as seen here.
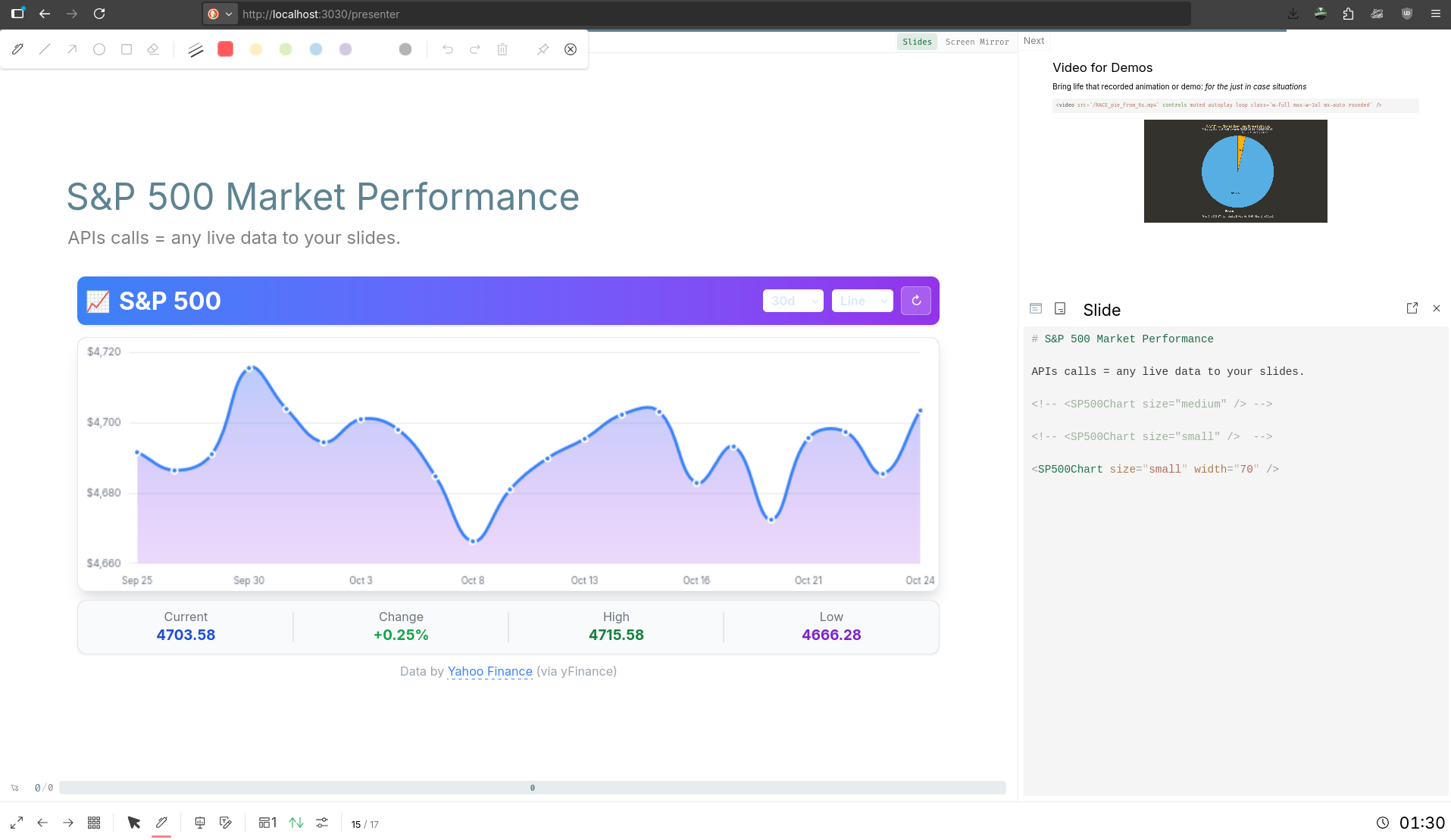 PPTs as a Code with SliDev
PPTs as a Code with SliDev SliDev Editor Repository
SliDev Editor RepositoryGrok API
Few weeks ago I was tinkering with grok API, which can be used also via LiteLLM.
And just this week I got…
Perplexity API
… Perplexity PRO access.
It feels great to get life/search data from the internet.
https://github.com/JAlcocerT/Streamlit-MultiChat/tree/main/Z_Tests/PerplexityAPI
https://jalcocert.github.io/JAlcocerT/live-search-and-research-with-ai/#perplexity 🐍
curl https://api.perplexity.ai/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "sonar-pro",
"messages": [
{
"role": "user",
"content": "What are the major AI developments and announcements from today across the tech industry?"
}
]
}' | jqConclusions
Does it even make sense to try building an AI Saas?
I would say yes, for the learnings.
For the financial motivations, just be aware of Pareto and that most tries will fail.
The OpenAI LLM approach was good enough for this PoC and I did not end up plugging Codex CLI.
You could also try LangChain Agents approach as per this cfe video
Mermaid x Excalidraw
We might find some concepts that are hard to explain with words.
But having these awsome OSS tools for quick diagraming or sketching, there are no excuses allowed :)
Dont choose between Mermaid or Excalidraw.
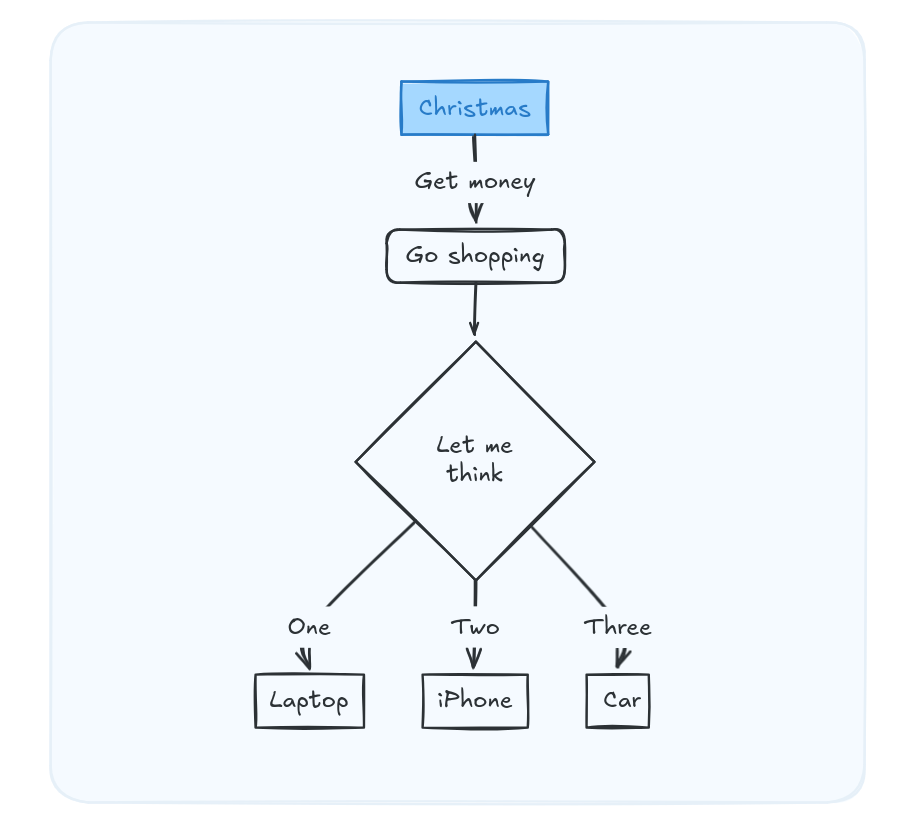
flowchart TD
A[Christmas] -->|Get money|
B(Go shopping)
B --> C{Let me think}
C -->|One| D[Laptop]
C -->|Two| E[iPhone]
C -->|Three| F[fa:fa-car Car]BTW, these diagrams look very well when combined with a proper wiki/documentation on how your dev/D&A project works.
 Excalidraw for D&A
Excalidraw for D&A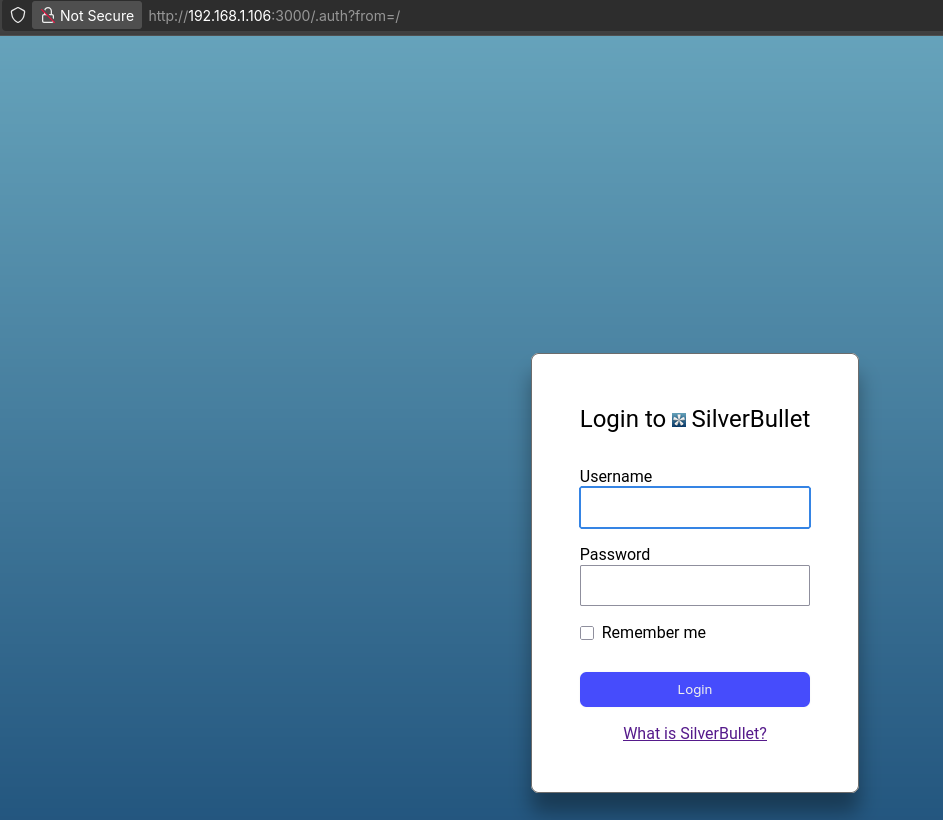 Flat Files KB
Flat Files KB- https://github.com/excalidraw/excalidraw-libraries
- https://libraries.excalidraw.com/?theme=light&sort=default
Mermaid x Tech Talk
Ive prepared a tech talk about this mermaid x openAI setup:
git clone https://github.com/JAlcocerT/slidev-editor
#git branch -a
#git checkout -b logtojseauth main
#git status --porcelain && echo "---" && git pull origin logtojseauth
#git show --stat d21233214c504640056180db03c9c98edd06c1aeI also promised myself that this is the last presentation that i will do this year.
Consider adding such SliDev VUE Components like this one you can generate QRs!
Ive also done few other tech talks previously:
Including, how to run LLMs locally: from Q1 2024!
FAQ
Others ppts ive worked on and how to run them
git clone https://github.com/JAlcocerT/slidev-editor.git
#cd slidev/slidev-ba-tech-talk-exadel
#npm install
#npm run devRemember that you need the ./public folder to provide custom background assets!
Last one from here, was this ppt on…slidev ppts as a code!
Architecture and Icons
If you are a D&A Architect, consider: