My Favourite ways to RAG
Intro
If you are already familiar with Python:
And have been tinkering with ways to chat with data context…
 Flask Intro
Flask Intro Data Chat Repo
Data Chat RepoThese should be some familiar RAG frameworks so far:
We will also see some trendy AI tools that work with RAGs as well:
- MLFlow - For observability (from ML to AI)
- LangGraph - Programatic agents workflows. See the docs
- LangFlow - Low code environment to build AI Apps ~ Flwise
- LangFuse - Observability for AI ~LangSmith but MIT
LangChain
For now, the most popular RAG framework!
Web Scrapping
LangChain can also help us to chat with website content:
In this case, With Ollama and ChromaDB.
With Persistent ChromaDB and MD
You can build this around a Flask webapp:
- app.py
- index.html
CSV and PDF
Wherever office work you have, you will most certainly see 2 kind of files: spreadsheets (CSVs) and pdfs.
Thanks to langchain, we can ask information contained in both kind of files:
For PDF’s you can do:
If you are interested, you can edit PDFs with:
See also: stirlingPDF,…
Database
Further into data analytics, you will want to chat directly with the content of your databases:
This can be very valuable for real estate applications as seen here
LangChain Agents
But thats a topic beyond RAG, with Agents:
Multi-Agents FrameworksMulti Agents RepoLLamaIndex
A competitor in the RAG space for Langchain is LLamaIndex
I also learnt a lot with the chat over .md files with LlamaIndex + Mem0.
PandasAI
This was the first RAG I heard about 2 years ago.
Conclusions
Remember that there are already some alternatives to RAGS: like MCP or KBLM
For now, my favourite one is still LangChain for its various use cases:
![]()
For a simpler local RAG setup, have a look to these.
Trendy AI Concepts
Concepts / AI Tools that are veeery trendy, also as seen here
Reranking models for RAG - As it can be done with LocalAI!
Summarization Techniques: https://python.langchain.com/v0.1/docs/use_cases/summarization/
Hypothetical Documents Embeddings: https://python.langchain.com/v0.1/docs/use_cases/query_analysis/techniques/hyde/
MultiVector Retrieval
ReACT fwk
MLFlow
MLflow/mlflow: Open source platform for the machine learning lifecycle
LangChain, LLamaindex, OpenAI… can all be used together with MLFlow! https://mlflow.org/docs/latest/llms/
What for?
It helps us see/observe how our LLMs are working in production.
From this simple prompts: https://github.com/JAlcocerT/Streamlit-MultiChat/blob/main/Z_Tests/OpenAI/openai_mermaid.py
To This one: https://github.com/JAlcocerT/Streamlit-MultiChat/blob/main/Z_Tests/OpenAI/openai_t2t-o1mini.py
To….
import mlflow
mlflow.set_tracking_uri(uri="http://<host>:<port>")##pip install mlflow==2.21.3
mlflow server --host 127.0.0.1 --port 8080
from openai import OpenAI
import mlflow
client = OpenAI(api_key="<YOUR_API_KEY>")
# Set MLflow tracking URI
mlflow.set_tracking_uri("<YOUR_TRACKING_URI>")
# Example of loading and using the prompt
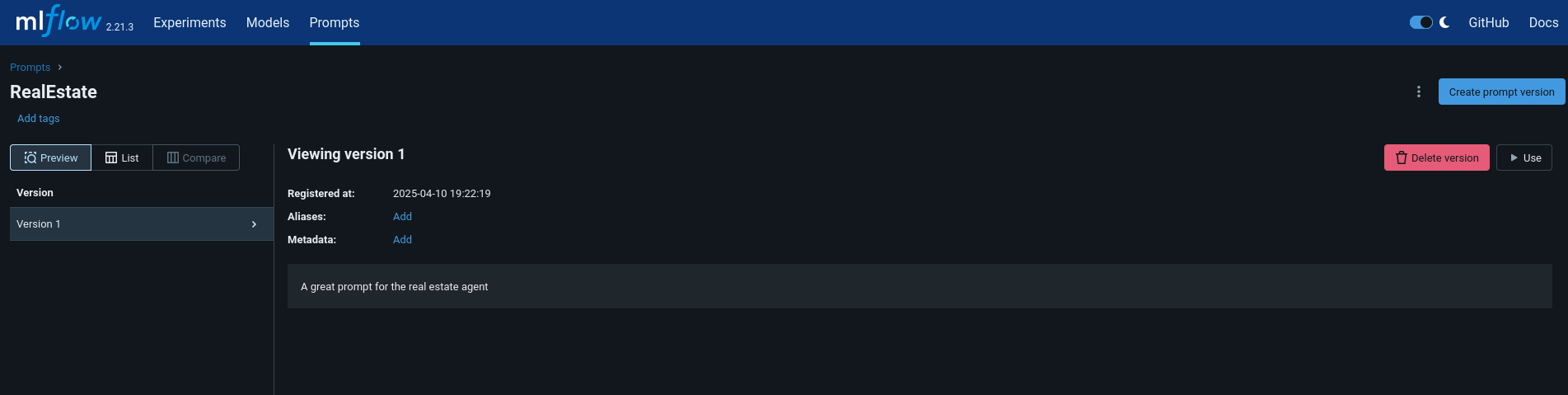
prompt = mlflow.load_prompt("prompts:/RealEstate/1")
response = client.chat.completions.create(
messages=[{
"role": "user",
"content": prompt.format(),
}],
model="gpt-4o-mini",
)
print(response.choices[0].message.content)MLflow Tracing provides LLM observability for various GenAI libraries such as OpenAI, LangChain, LlamaIndex, DSPy, AutoGen, and more.
To enable auto-tracing, call mlflow.xyz.autolog() before running your models.
Refer to the documentation for customization and manual instrumentation.
LangGraph BigTool
LangGraph is a Python library for building stateful, multi-agent systems and complex conversational workflows.
MIT | Build resilient language agents as graphs.
The LangGraph library enables agent orchestration — offering customizable architectures, long-term memory, and human-in-the-loop to reliably handle complex tasks.

Build LangGraph agents with large numbers of tools
LangFlow
Langflow’s primary strength lies in its visual, low-code environment for building AI applications, especially those leveraging LLMs and LangChain.
docker run -it --rm -p 7860:7860 langflowai/langflow:latest
LangFuse
LangFuse is an Equivalent to LangSmith for observability but MIT and selfhostable
FAQ
MLflow on Databricks: Review how MLflow is integrated into Databricks for tracking machine learning experiments, managing models, and deploying them.
Understand concepts like runs, experiments, and the model registry.
AI Keys
Lately I have been using:
- https://claude.ai/
- https://console.anthropic.com/workbench/
- https://console.groq.com/keys
- https://platform.openai.com/api-keys
GEN AI Techniques
- Fundamentals of Neural Networks: Understand the architecture and training of deep neural networks.
- Generative Adversarial Networks (GANs): Basic understanding of how GANs work for generating synthetic data or other creative outputs.
- Variational Autoencoders (VAEs): Another type of generative model.
- Transformer Networks: Deep dive into the architecture of Transformers, which are the foundation for many state-of-the-art NLP and generative models (e.g., BERT, GPT).
- Large Language Models (LLMs): Understand the capabilities and limitations of LLMs and how they can be applied to HR-related tasks.
See how to run LangGraph or MLFlow
AI Apps Im SelfHosting
Flask IntroFlask Sensor DisplaySelfHosted RAGs
- PrivateGPT
https://github.com/zylon-ai/private-gpt https://docs.privategpt.dev/overview/welcome/introduction
- QUIVIR - https://github.com/QuivrHQ/quivr
Opiniated RAG for integrating GenAI in your apps 🧠 Focus on your product rather than the RAG. Easy integration in existing products with customisation! Any LLM: GPT4, Groq, Llama. Any Vectorstore: PGVector, Faiss. Any Files. Anyway you want.
Groq YT Summarizer
docker pull ghcr.io/jalcocert/phidata:yt-groq:latest #:v1.1 #:latestMultiChat
docker pull ghcr.io/jalcocert/streamlit-multichat:latest #:v1.1 #:latestLocal Deep Researcher
A very interesting project that makes web search and summarizes them:
MIT | Fully local web research and report writing assistant
Setup Ollama as per:
- https://github.com/JAlcocerT/Docker/tree/main/AI_Gen/Ollama
- https://fossengineer.com/selfhosting-llms-ollama/
docker run -d --name ollama -p 11434:11434 -v ollama_data:/root/.ollama ollama/ollama
docker exec -it ollama ollama --version
docker exec -it ollama sh
ollama pull deepseek-r1:8bMake sure to adapt the .env:
LLM_PROVIDER=ollama
OLLAMA_BASE_URL="http://localhost:11434" # Ollama service endpoint, defaults to `http://localhost:11434`
LOCAL_LLM=model # the model to use, defaults to `llama3.2` if not setYT Vid Summarized with Groq | Local Deep Researcher📌
Summarized with this groq project.
The video explores the new fully open source reasoning model, DeepSeek-R1, which represents a new scaling paradigm for Large Language Models (LLMs).
The model is trained using a combination of fine-tuning and reinforcement learning, and its training strategy is described in detail. The video also demonstrates the capabilities of the model, including its ability to reason and generate comprehensive summaries.
The Training Strategy of DeepSeek-R1
DeepSeek-R1 uses a combination of fine-tuning and reinforcement learning to produce a strong reasoning model.
The first stage involves fine-tuning a strong base chat model, DeepSeek V3, on thousands of chain of thought reasoning examples.
The second stage uses reinforcement learning with a rule-based reward function to score the model’s outputs.
The model generates 64 different attempts to solve a problem and scores each one, increasing or decreasing the probability of generating tokens based on the score.
This process helps the model discover good reasoning patterns.
Filtering and Fine-Tuning
The model’s outputs are filtered to get high-quality reasoning traces, which are then used for further fine-tuning.
This process helps restore general model capabilities while baking in high-quality reasoning. The final stage involves a second round of reinforcement learning with different rewards, including helpfulness and harm.
Results and Distillation
The results show that DeepSeek-R1 is on par with other state-of-the-art reasoning models, including the O Series models from OpenAI.
The model is also distilled into smaller models, including a 14 billion parameter model that can run on a laptop.
Playing with DeepSeek-R1
The video demonstrates the capabilities of DeepSeek-R1, including its ability to generate summaries and reason about complex topics.
The model is shown to be very expressive, emitting think tokens that provide insight into its thought process.
The video also explores the use of Json mode, which strips away think tokens and provides a cleaner output.
Takeaways:
- DeepSeek-R1 represents a new scaling paradigm for LLMs, using reinforcement learning to discover good reasoning patterns.
- The model’s training strategy involves a combination of fine-tuning and reinforcement learning, with filtering and fine-tuning to restore general capabilities.
- The model is capable of generating comprehensive summaries and reasoning about complex topics.
- The distillation of the model into smaller versions, such as the 14 billion parameter model, makes it possible to run on a laptop.
RAG x Ollama
Ollama makes it easy to get up and running with large language models locally. It is like Docker for managing LLMs.
With modelfile, it creates a profile of a model: ollama create your_model_profile -f ./testmodelfile
ollama run testmodelfileInstall it with docker or with CLI:
- https://hub.docker.com/r/ollama/ollama
- https://gpt-index.readthedocs.io/en/stable/examples/llm/ollama.html
Using Ollama with RAGs 📌
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
podman run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama#sudo systemctl status ollama
#sudo systemctl stop ollama#version: '3'
services:
ollama:
image: ollama/ollama:latest #0.1.17
container_name: ollama
ports:
- "11434:11434" #Could also be any free local port like 9999:11434
volumes:
- ai_ollama_data:/root/.ollama
volumes:
ai_ollama_data:
ollama run orca-mini:3b
#http://localhost:11434/
# #network_mode: host