Customizing a Web for Mental Health Care
Intro
Recently, I was talking with a friend and we found out about:
Competitors / The initial site:
* https://www.docplanner.com/
* https://www.doktortakvimi.com/
* https://pro.doktortakvimi.com/fiyatlandirma
* https://www.psikolognevinkeskin.com/
* https://www.psikolojisaati.com/
- Chosen Domain:
psikolognevinkeskin.info
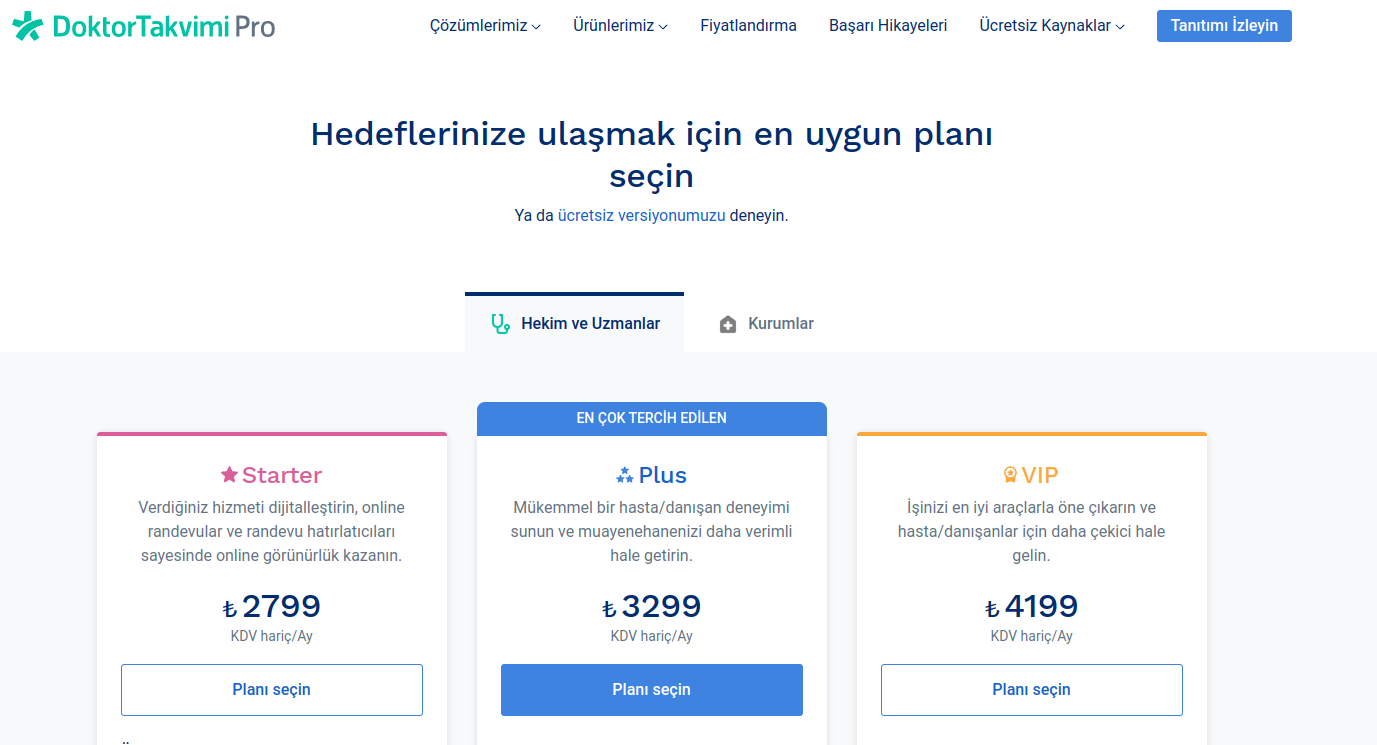
Analyzing the Initial Status
Broken links? LinkChecker ⏬
- Use LinkChecker with the GHCR Container Image, which is x86 only.
# docker run --rm -it -u $(id -u):$(id -g) ghcr.io/linkchecker/linkchecker:latest --verbose https://https://www.psikolognevinkeskin.com/
podman run --rm -it ghcr.io/linkchecker/linkchecker:latest --verbose https://www.psikolognevinkeskin.com/ > linkchecker_psyc.txtResulting at:
That's it. 53 links in 53 URLs checked. 5 warnings found. 0 errors found.
Stopped checking at 2024-10-19 07:34:09+000 (12 seconds)FireCrawl Setup
So 53 urls on the site, sounds like the moment to use FireCrawl and get the content.
FireCrawl with Python 📌
Full code is in my repo, here.
You will need the FireCrawl API and a code like below, which scraps a single url.
We dont need the crawling capabilities, as the web is a single pager.
from firecrawl import FirecrawlApp
from dotenv import load_dotenv
import os
# Load environment variables from .env file
load_dotenv()
# Get the API key from environment variable
api_key = os.getenv('FIRECRAWL_API_KEY')
# #app = FirecrawlApp(api_key='fc-yourapi')
if api_key is None:
raise ValueError("API key not found in environment variables")
# Initialize the FirecrawlApp with the API key
app = FirecrawlApp(api_key=api_key)
# URL to scrape
url = 'https://www.psikolognevinkeskin.com'
# Scrape the data
scraped_data = app.scrape_url(url)
# Write the output to a file using UTF-8 encoding
with open("output_nevin2.txt", "a", encoding="utf-8") as f:
f.write(str(scraped_data) + "\n")The magic happened, and now we have json like web information saved in a txt.
Tools for easier JSON 📌
In the Big Data PySpark post, we got to use: jsonformatter, but there are more.
https://github.com/josdejong/jsoneditor - A web-based tool to view, edit, format, and validate JSON
https://github.com/AykutSarac/jsoncrack.com - ✨ Innovative and open-source visualization application that transforms various data formats, such as JSON, YAML, XML, CSV and more, into interactive graphs.
But actually, FireCrawl provides markdown, ready for LLMs:
Tools for easier markdown 📌
And time to translate. Yea, the original site its in turkish, and initially I went the googletranslation way, but the pkg is outdated and i got conflicts with httpx.
Time to try deep_translator.
And the test went fine.
Proposed Themes
Both probably an overkill, coming from a single pager.
So I proposed this as a landing single pager or this as sth more advance with blog as well, portfolio - Both MIT Licensed.
Testing Proposed Astro Themes | Morita Web WithAstro Astro Theme 📌
git clone https://github.com/withastro/astro
cd ./examples/portfolio
npm install
npm run devEverything worked, so i created this repo for the project
npm run build
npm install -g serve #serve with npm
serve -s dist #http://localhost:3000And I used Cloudflare together with github, for the demo deployment.
Conclusions
Other THemes for Doctors:
- https://github.com/cssninjaStudio/dokto
- https://github.com/mhyfritz/astro-landing-page
- https://github.com/withastro/astro/tree/main/examples/portfolio
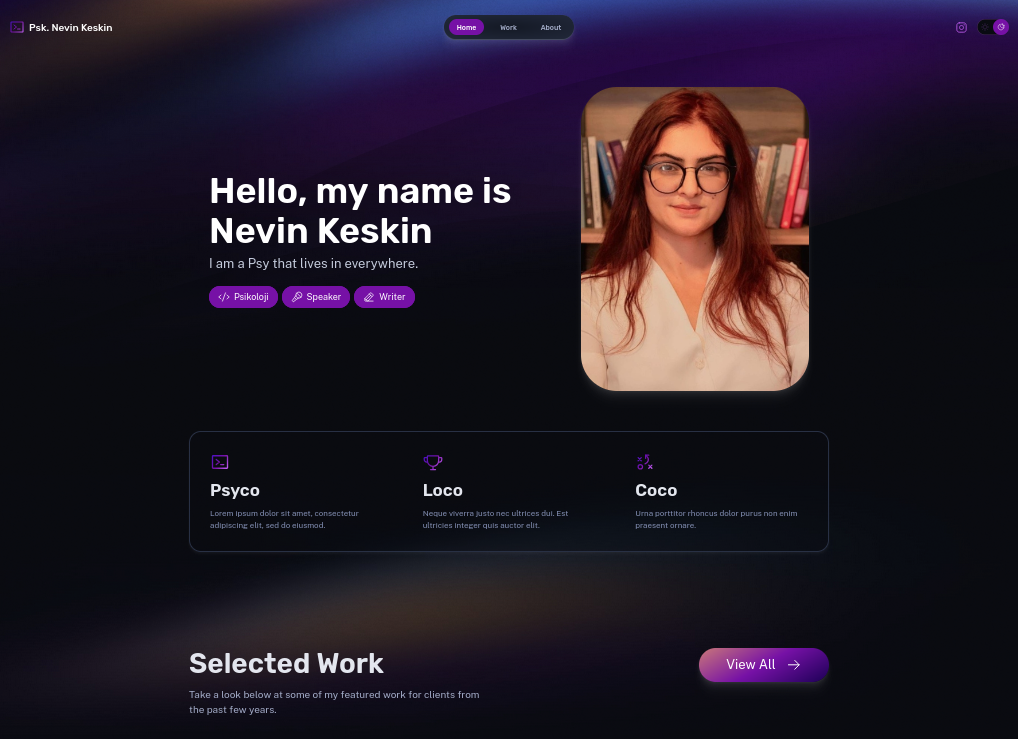
The final result:
Withastro/astro the example portfolio theme was the selected one for this case!
npm create astro@latest -- --template portfolioThe result was available, after few minutes here: https://morita-web.pages.dev/
There is always the possibility to add cal.com embedded or via links CTAs like this one: https://cal.com/jalcocertech/consulting
Also, you can put some whatsapp bouble via astro components, as seen here

You can combine the WA with the cal.com bouble:

FAQ
Docker Artifacts for Astro Websites
#https://hub.docker.com/_/node
# Stage 1: Build the Astro site
FROM node:22.16-alpine3.22 as builder
WORKDIR /app
# Copy package.json and package-lock.json
COPY package*.json ./
# Install dependencies
RUN npm install
# Copy the rest of the source code
COPY . .
# Build the Astro site
RUN npm run build
# Stage 2: Serve with Nginx
FROM nginx:alpine
# Copy the built site from the builder stage
COPY --from=builder /app/dist /usr/share/nginx/html
# Expose port 80
EXPOSE 80
# Start Nginx server
CMD ["nginx", "-g", "daemon off;"]#version: '3'
services:
# Run one of these two Astro services at a time by specifying it directly with the command
# e.g., docker-compose up astro-dev astro-prod
# Astro Development Server
astro-dev:
image: node:22.16-alpine3.22 #node:18-alpine
container_name: astro-dev
working_dir: /app
ports:
- "4324:4321" # Astro dev server with live changes port - Go to http://localhost:4324/
volumes:
- /home/jalcocert/WebifAI/Astro-Themes/morita-web:/app #this is a common volume for Astro container to place the .md post
command: sh -c "cd /app && npm install && npm run dev -- --host 0.0.0.0"
environment:
- NODE_ENV=development
networks:
- project-network
tty: true
restart: "no"
astro-prod:
image: node:22.16-alpine3.22 #node:18-alpine #docker pull node:22.16-alpine3.22
container_name: astro-prod
working_dir: /app
volumes:
- /home/jalcocert/WebifAI/Astro-Themes/morita-web:/app #this is a common volume for Codex container to place the .md post
ports:
- "8087:4321" # Changed to match Astro's default port
command: >
sh -c "cd /app &&
npm install &&
npm run build &&
npx http-server ./dist -p 4321"
#check 2 commands for same container (?)
environment:
- NODE_ENV=production
networks:
- project-network
restart: "no"
networks:
project-network:
name: project-documentation-network