Bots
Bots are one of those things that are easy to get started with, but can be complex to get right.
And many clients will want one to be embeded into their sites.
You might be here because have seen/used Telegram bots.
But dont get confused with chatbots vs automation: despite tools like n8n being able to handle bots
Telegram Bots
Some people get creative with telegram https://github.com/ccbikai/BroadcastChannel
Turn your Telegram Channel into a MicroBlog.
But we are here to build custom tg bots.
TG Bots - 101 Setup 📌
N8N Bots
You can combine TG bots with Telegram.
Having your AI APi Keys ready and your n8n setup first:
N8N x Telegram Bots 📌
Other Bots
Flowise AI
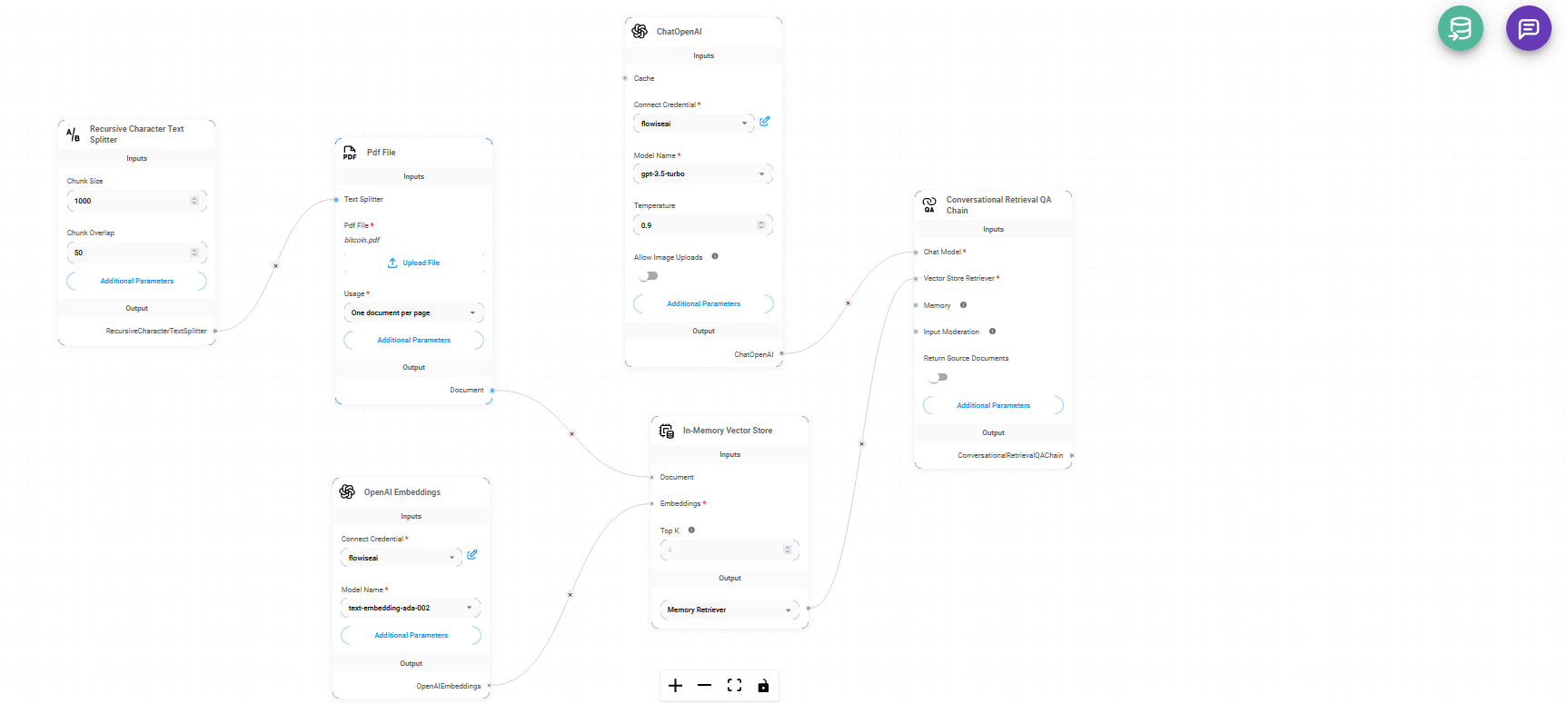
Custom Bots
These days you will hear the term RAG.
These can be applied in many business domains, like for real estate agencies
Also, to provide custom QnA for your landing Pages/SaaS
The good news?
That If you are in good terms with front end tools like astro and dont mind coding some Python backend - you can get away and make your own custom chatbot.
From visuals, to the knowledge, the way it replies and who can use it.
Go from this:
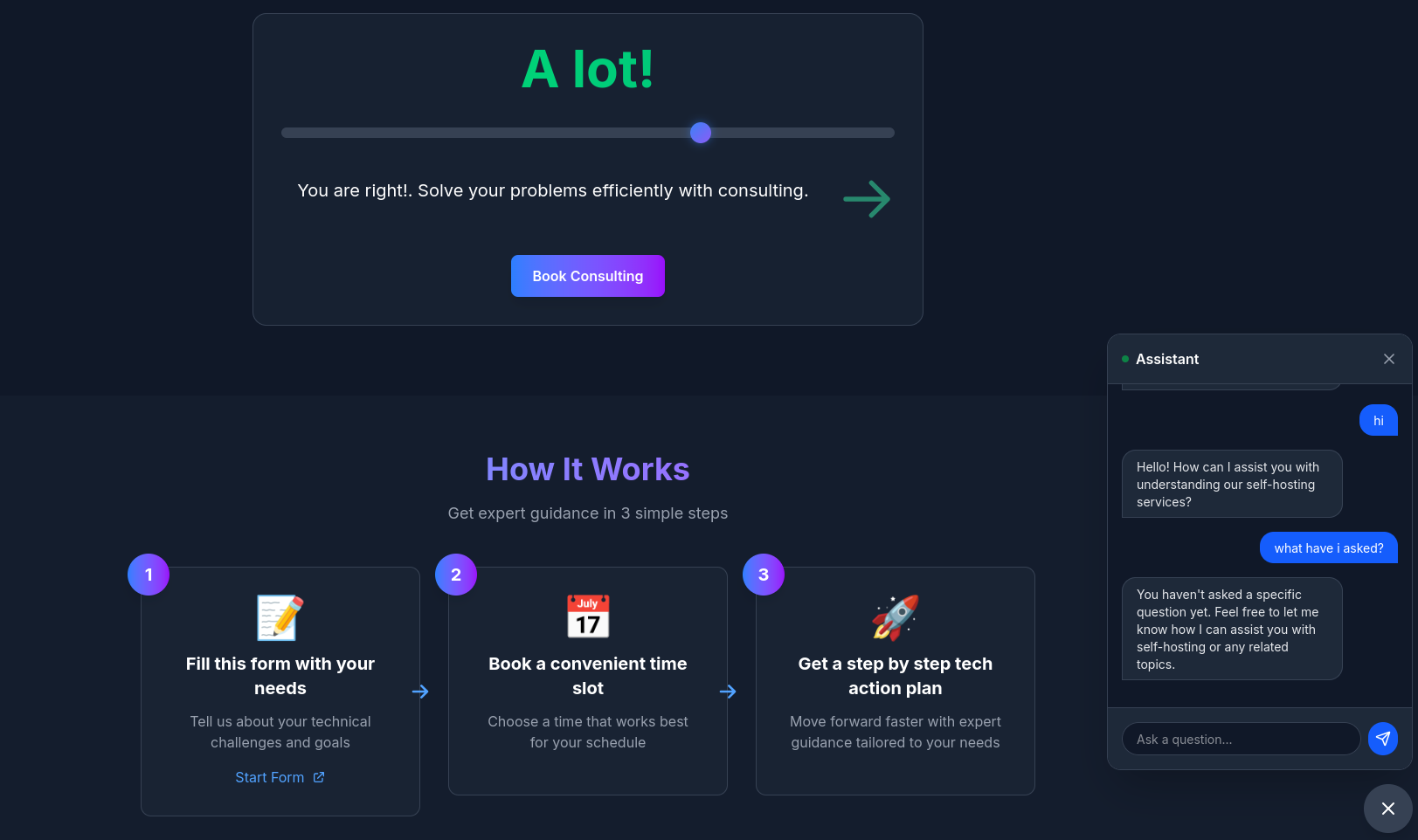 Custom Bots for Landing Pages
Custom Bots for Landing Pages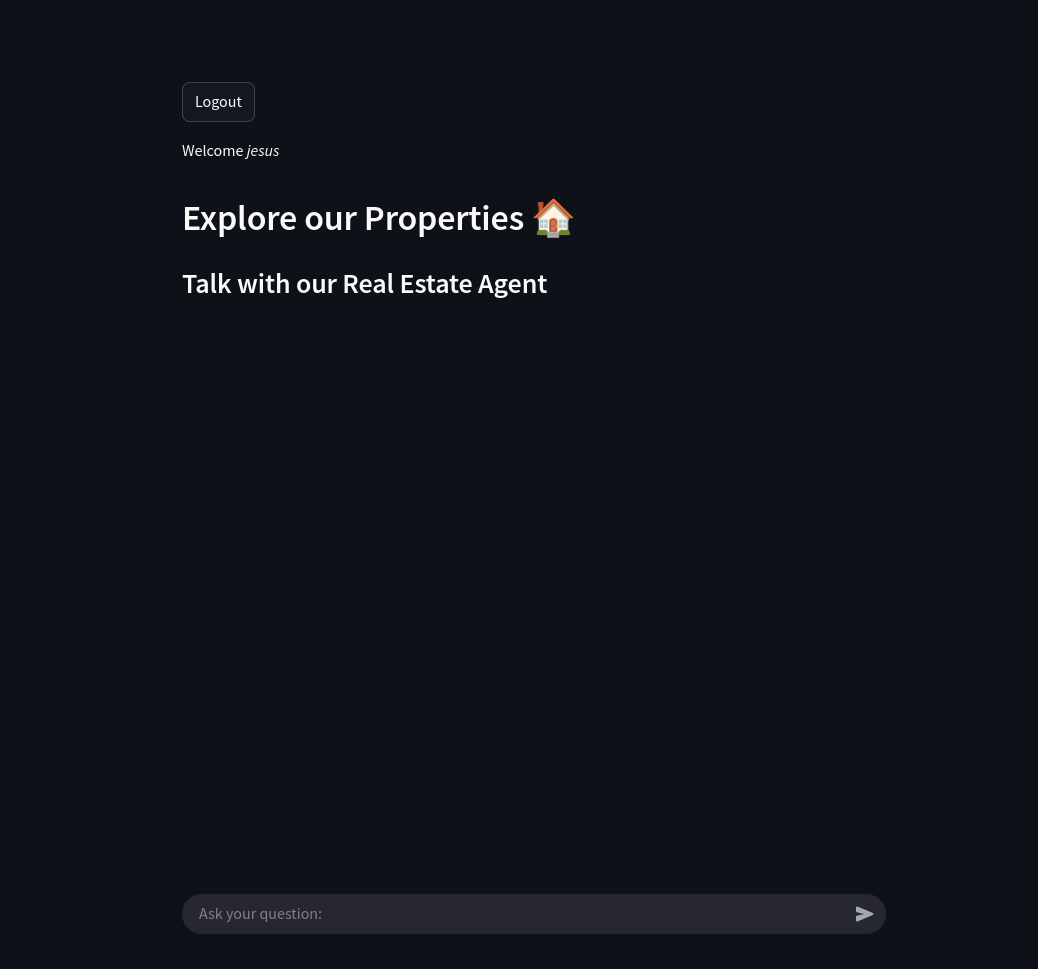 Custom Bots for RE
Custom Bots for RETo this: as seen here


Hosted Models
You need to plug something to that cool UI/UX and backend with the bot logic.
Interesting AI via APIs 📌
- Groq - https://console.groq.com/keys
- OpenAI - https://platform.openai.com/account/api-keys
- Anthropic - https://console.anthropic.com/api-keys
source .env
#export OPENAI_API_KEY=sk-proj-...
#Like these LLM API endpoints:
- Open AI - GPT APIs https://platform.openai.com/api-keys
- Groq - https://console.groq.com/keys
- Gemini (Google) - https://ai.google.dev/gemini-api/docs
- Mixtral - Open Models, you can use their API
- Anthropic (Claude) - https://www.anthropic.com/api
- Grok (Twitter)
- Azure
Bots x Knowledge Base
If you have a company and are having a KB based on flat files.
Like SilverBullet, Logseq, Flatnote or Raneto:
Consider also WikiJS or OtterWiki:
And plug your knowledge sources via RAG / vector DBs / embeddings:
SelfHosted Landing Repo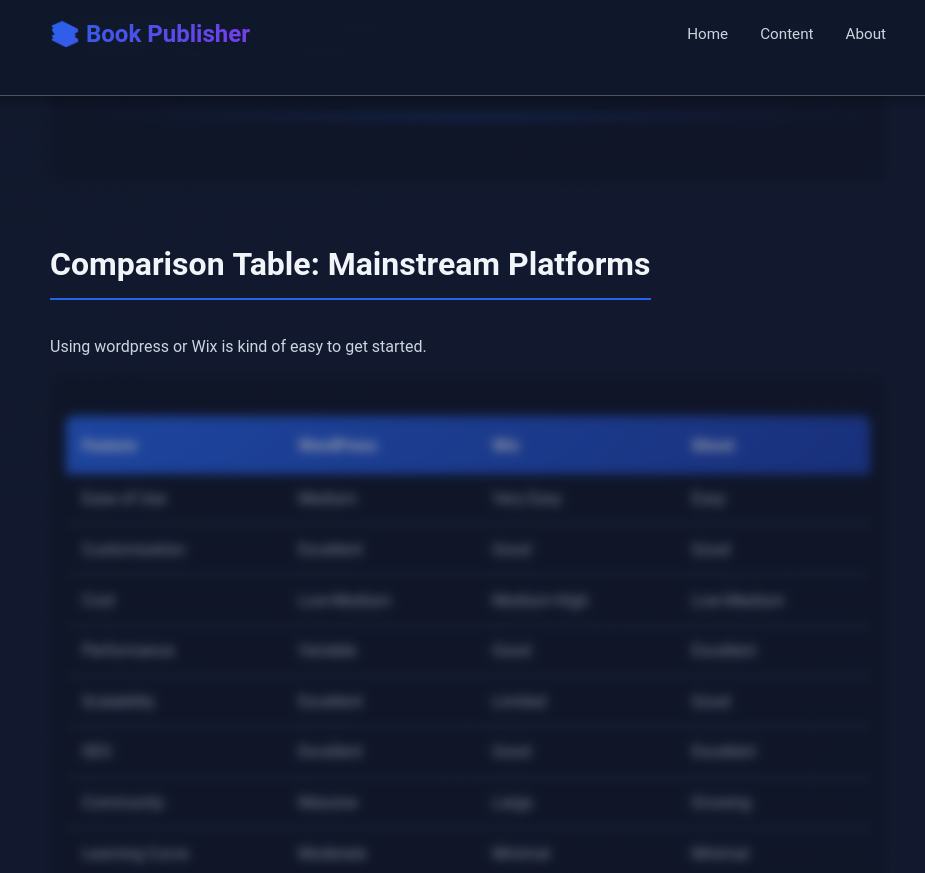 DIY webs via webook
DIY webs via webookThese markdown based notes need somewhere to be hosted.
Like a PaaS or a deployment on companies resources.
What you get?
From team knowledge to internal chatbot knowledge. Avoid silos. Build internal transparency
You Mean Scrapping?
Some people look for ,bot’ scrappers.
And Ive been commenting about those in few occasions.
To understand these tools, it helps to think of them as building blocks for a house.
BeautifulSoup is a specialized tool (like a hammer), Crawlee is the construction management system (the blueprint and workers), and Apify is the land and infrastructure where the house is built.
- What is Crawlee?
Crawlee is an open-source web scraping and browser automation library. It doesn’t just “scrape” a page; it manages the entire “crawl” (moving from link to link).
- What it does: It handles the difficult “plumbing” of web scraping: automatic retries, proxy rotation, session management, and running tasks in parallel.
- The Problem it Solves: Normally, if you scrape a site and it crashes or blocks your IP, your script dies. Crawlee automatically manages these failures so your scraper keeps running.
- Ecosystem: It was originally built for JavaScript/Node.js but was expanded to Python in mid-2024.
- How it relates to Apify
Apify is the company that created Crawlee. Think of them as the “Enterprise” version of the tool.
- The Relationship: Crawlee is the open-source engine. You can download it for free and run it on your own computer or server.
- The Platform: Apify is a cloud platform (PaaS) where you can host your Crawlee scrapers. If you don’t want to worry about managing servers, databases, or scheduling, you “push” your Crawlee code to Apify, and they run it for you.
- Evolution: Previously, these were one big tool called the “Apify SDK.” They split them so that developers could use the powerful scraping features (Crawlee) without being forced to use the Apify cloud.
- How it relates to BeautifulSoup (BS4)
BeautifulSoup is an HTML parser. It is excellent at reading a piece of HTML and finding specific tags (like “find all headers” or “get this price”).
Crawlee and BS4 are partners, not competitors.
- Crawlee’s job: It goes to the website, handles the connection, avoids getting blocked, and downloads the HTML.
- BS4’s job: Once Crawlee has the HTML, it hands it to BeautifulSoup to extract the actual data.
In the Python version of Crawlee, there is a specific class called BeautifulSoupCrawler. It essentially wraps BS4 inside a professional crawling engine.
| Feature | BeautifulSoup (BS4) | Crawlee | Apify |
|---|---|---|---|
| Type | Library (Parser) | Framework (Crawler) | Platform (Cloud) |
| Primary Goal | Extract data from HTML | Manage the scraping process | Run scrapers at scale |
| Handles Proxies? | No | Yes | Yes (Paid proxies) |
| Handles Retries? | No | Yes | Yes |
| Where it runs? | Anywhere Python runs | Anywhere Python runs | In the cloud |