Local Audio with AI
Coqui TTS
MPL | 🐸💬 - a deep learning toolkit for Text-to-Speech, battle-tested in research and production
Eager to spin a Coqui Text to speech local server?
docker run -d \
--name coquitts \
-p 5002:5002 \
--entrypoint python3 \
ghcr.io/coqui-ai/tts-cpu \
TTS/server/server.py \
--model_name \
tts_models/en/vctk/vitsIt will go with the en/vctk/vits model. But you can change it later on.
The web ui will be at port 5002:
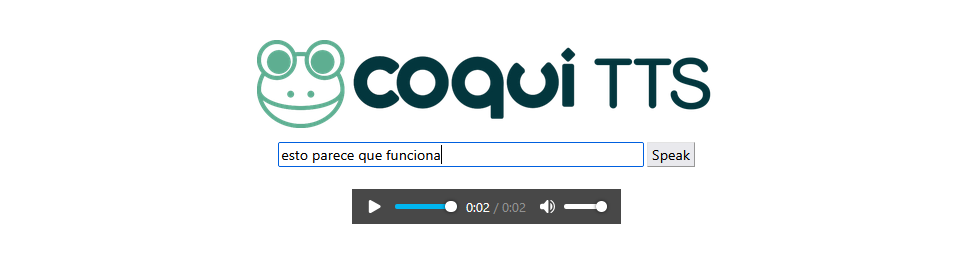
And it works with more language than EN as well!
Deploy with the related docker-compose for CoquiTTS.
Deploy CoquiTTS with Docker | CLI Details 📌
docker exec -it coquitts /bin/bash
docker run --rm -it -p 5002:5002 --entrypoint /bin/bash ghcr.io/coqui-ai/tts-cpu
python3 TTS/server/server.py --list_models #To get the list of available models
python3 TTS/server/server.py --model_name tts_models/en/vctk/vits # To start a server
#python3 TTS/server/server.py --model_name tts_models/es/mai/tacotron2-DDCservices:
tts-cpu:
image: ghcr.io/coqui-ai/tts-cpu
container_name: coquitts
ports:
- "5002:5002"
entrypoint: /bin/bash
tty: true
stdin_open: true
# Optional: Mount a volume to persist data or access local files
# volumes:
# - ./local_data:/dataserver.py is a Flask App btw :)Bark
https://github.com/suno-ai/bark
More
xTTS2
Text to Speech with xTTS2 UI, which uses the package: https://pypi.org/project/TTS/
Meaning CoquiTTS under the hood
MIT | A User Interface for XTTS-2 Text-Based Voice Cloning using only 10 seconds of speech
The model used
- https://coqui.ai/cpml.txt
- Hardware needed: works with CPU ✅
Installing xTTS2 with Docker. Clone audio locally.
git clone https://github.com/pbanuru/xtts2-ui.git
cd xtts2-ui
python3 -m venv venv
source venv/bin/activateGet the right pytorch installed: https://pytorch.org/get-started/locally/
#pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
pip install -r requirements.txt#version: '3'
services:
audio:
image: python:3.10-slim
container_name: audio
command: tail -f /dev/null
volumes:
- ai_audio:/app
working_dir: /app # Set the working directory to /app
ports:
- "7865:7865"
volumes:
ai_audio:podman exec -it audio /bin/bash
python --versionapt update
apt install git
#git --version
git clone https://github.com/BoltzmannEntropy/xtts2-ui
cd xtts2-ui
#python -m venv venvaudio
#pip3 install torch torchvision torchaudio && pip install -r requirements.txt && pip install --upgrade TTS && streamlit run app2.py
pip3 install torch torchvision torchaudio #https://pytorch.org/get-started/locally/
pip install -r requirements.txt
pip install --upgrade TTS
streamlit run app2.py Streamlit UI
streamlit run app2.py Flask Intro
Flask Intro Flask Sensor Display
Flask Sensor Displaytext_generation_webui_xtts
https://github.com/kanttouchthis/text_generation_webui_xtts/
Conclusions
Making these with portainer is always easier:
sudo docker run -d -p 8000:8000 -p 9000:9000 --name=portainer --restart=always -v /var/run/docker.sock:/var/run/docker.sock -v portainer_data:/data portainer/portainer-ce
# docker stop portainer
# docker rm portainer
# docker volume rm portainer_dataClone Audio
Taking some help from yt-dlp: https://github.com/yt-dlp/yt-dlp
Unlicensed| A feature-rich command-line audio/video downloader
yt-dlp -x --audio-format wav "https://www.youtube.com/watch?"
yt-dlp -x --audio-format wav "https://www.youtube.com/watch?v=5Em5McC_ulc"Which I could not get working, nor: https://github.com/ytdl-org/youtube-dl
sudo apt install youtube-dl
youtube-dl -x --audio-format mp3 "https://www.youtube.com/watch?v=5Em5McC_ulc"FAQ
https://github.com/kanttouchthis/text_generation_webui_xtts/?tab=readme-ov-file
With Oobaboga Gradio UI
And its extensions: https://github.com/oobabooga/text-generation-webui-extensions
Voice?
Generally, here you can get many ideas: https://github.com/sindresorhus/awesome-whisper
Also, in HF there are already interesting projects.
ecoute (OpenAI API needed)
Meeper (OpenAI API needed)
Bark
Whisper - https://github.com/openai/whisper
Linux Desktop App:
flatpak install flathub net.mkiol.SpeechNote
flatpak run net.mkiol.SpeechNote