My Fav Web browsers & their automation
Tl;DR
Playing again with scrappers: scrapegraph, crawl4ai, firecrawl.
 Job Trends RepoScrapping Repo
Job Trends RepoScrapping RepoIntro
Browser automation is a thing.
Specially if we combine it with LLMs:
MIT | 🌐 Make websites accessible for AI agents. Automate tasks online with ease.
{
"mcpServers": {
"browser-use": {
"command": "uvx",
"args": ["browser-use[cli]", "--mcp"],
"env": {
"OPENAI_API_KEY": "sk-..."
}
}
}
}Browsers Ive tried
Even a CLI browser called Lynx: https://jalcocert.github.io/JAlcocerT/scrapping-with-llms/#faq
sudo apt install lynx
lynx duckduckgo.com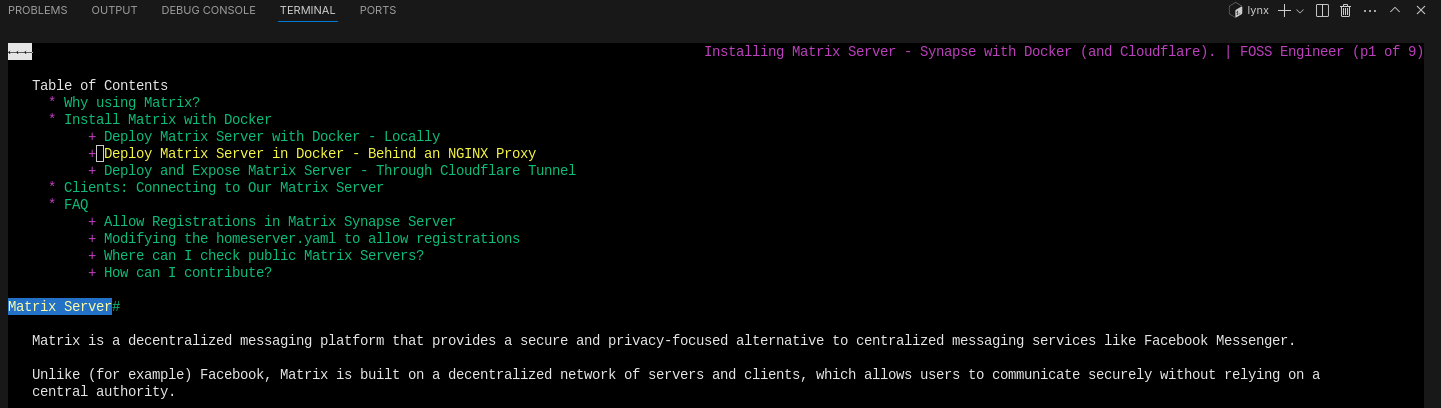
Lately I tried Zen browser: https://zen-browser.app/download/
With CTRL+ALT+C it gets really compact!
With CTRL+H, it opens your synced tab, so you can see your mobile firefox tabs on desktop
#pkill -9 brave #brave was not behaving properly lately...
flatpak install flathub app.zen_browser.zenWelcome to a calmer internet | Firefox based
Zen offers a “Sync” feature, which is implemented using Mozilla Firefox’s Sync feature.
Which we could say is a modern UI version of firefox.
See how some people make money around KASM, where you can also browse:
https://www.youtube.com/watch?v=799uhYUxtvA
Automating your Browser
Playwright is an open-source browser automation library developed by Microsoft.
It is primarily used for fast, reliable, and cross-browser end-to-end testing of web applications.
Playwright allows developers to programmatically control browsers such as Chromium, Firefox, and WebKit through a unified API, supporting automation of user interactions, UI testing, and even web scraping.
Yes, Playwright is open source, available under the MIT license, and supports multiple programming languages including JavaScript, Python, C#, and Java.
It relates to web scraping because it can automate browser actions including navigation, interaction with page elements, and data extraction, thus enabling scraping of dynamically rendered web pages that simpler HTTP request libraries cannot handle effectively.
In summary:
- Playwright is a web automation tool focused on end-to-end testing.
- It is open source.
- It can be used for web scraping as well as testing, especially for sites with complex, dynamic, or JavaScript-rendered content.[2][3][4][7][10]
Playwright vs Pupeteer
Puppeteer and Playwright are both web automation tools that allow programmatic control of web browsers to automate tasks like testing, scraping, and interaction.
Puppeteer
- Puppeteer is a Node.js library developed by Google to control Chrome and Firefox via DevTools Protocol.
- It enables high-level browser automation: navigation, clicking, typing, taking screenshots, generating PDFs.
- Mainly focused on Chromium-based browsers with growing Firefox support.
- Pros: Simple API, great for Chrome automation, headless or headed modes, widely used for testing and scraping.
- Limitations: Primarily Chromium-focused (though Firefox is supported), limited cross-browser support, JavaScript/Node.js only.
Long back I saw https://github.com/unconv/gpt4v-browsing
Web Scraping with GPT-4 Vision API and Puppeteer
Playwright
- Playwright is an open-source automation framework by Microsoft supporting Chromium, Firefox, and WebKit (Safari) with one API.
- Supports multiple languages: JavaScript, Python, C#, and Java.
- Advanced features include multi-browser, multiple contexts, network interception, automatic waiting, mobile/device emulation, and visual testing.
- Pros: True cross-browser support, multi-language, built-in test runner (@playwright/test), robust automation for modern web apps.
- Limitations: Slightly more complex API, heavier dependency compared to Puppeteer but offers much broader capabilities.
Other notable web automation tools
I was using Selenium some time ago to help me download some reports automatically from an internal tool and then get their csv processed with R language.
But there are few others you could have a look to:
| Tool | Pros | Limitations |
|---|---|---|
| Selenium | Supports many languages and browsers, huge community, strong integration with CI/CD | Complex setup, slower, maintenance overhead, mobile testing limited |
| Cypress | Fast, developer-friendly, built-in waiting, real-time reloads | JavaScript only, limited browser support mainly Chromium, no multi-tabs or cross-domain |
| TestCafe | Easy setup, no browser drivers needed, supports parallel tests | JavaScript only, less flexible API, no XPath selectors |
| WebDriverIO | Modern JS API on Selenium, parallel tests, extensive plugins | Complex setup, depends on drivers, slower than direct browser APIs |
Summary
- Puppeteer: Great for Chrome-focused automation and quick JavaScript-based tasks.
- Playwright: More comprehensive, cross-browser, multi-language automation framework suitable for complex, cross-platform testing.
- Selenium: Most established with broad language and browser support but heavier setup.
- Others like Cypress, TestCafe offer specialized approaches with their own trade-offs.
These tools differ in browser support, language support, ease of setup, and test stability, so the choice depends on project needs and tech stack.
Scrapping Recap
I was tinkering with web scrapping tool for the job trends project.
With bs4 as a ~html+hardcoded places to look for info approach.
But in the AI times there are some interesting tools to look…
Not long ago I got to know about ApiFy
- Apify uses a subscription plus consumption (pay-as-you-go) model, with plans ranging from free to $999/month. It charges for compute units, proxy rental, storage, and support. The free plan includes $5 in monthly credits. For large-scale tasks, compute units cost between $0.20 and $0.30 each. Apify is ideal for scalable projects with varied needs and enterprise support.
Why APIfy? 🚀
Yes, using Firecrawl combined with n8n (an open-source automation tool) can achieve similar results to Apify in many cases, but with some differences:
Firecrawl provides fast, ready-to-use web data API with clean, structured data outputs optimized for AI and other use cases, similar to what Apify offers via its marketplace scrapers.
n8n allows building custom automation workflows visually, connecting Firecrawl’s API to other services (databases, APIs, notifications, etc.) without coding much, similar to how Apify manages task scheduling and integrations.
However, this approach requires more setup and maintenance because you need to build the workflows yourself and handle error handling, scaling, proxy management, and advanced scraping logic independently or with extra tools.
Apify packages all those complexities into one platform with built-in support, scalability, monitoring, and a large ecosystem. Using Firecrawl + n8n is more flexible and potentially cheaper but demands more technical effort and infrastructure management.
In short, Firecrawl + n8n is a powerful and flexible combo that can replicate Apify’s core functions but with higher setup/maintenance overhead and less out-of-the-box polish and tooling.
It suits teams with technical resources wanting customization and cost control.
Apify suits users wanting turnkey, scalable scraping and automation with minimal setup.
Firecrawl has a simple and predictable credit-based model: 1 page scraped equals 1 credit. The free plan allows for up to 500 pages, and paid plans range from $16 for 3,000 pages to $333 for 500,000 pages. This includes infrastructure, proxies, and bandwidth. It is a more economical choice for simple scraping tasks and moderate volumes.
ScrapeGraphAI offers annual plans with credits for requests and speed limits, ranging from a free plan with 50 credits to customized enterprise plans. It focuses on AI-powered scraping, with costs based on API calls or pages scraped. It provides support and scalable features, but exact prices vary depending on usage.
Crawl4AI is free software since it’s open source, but the real cost comes from the infrastructure and external LLM APIs used for extraction and processing. This means the costs are variable and depend on the scale and external services you connect.
| Platform | Pricing Model | Approximate Costs | Best for |
|---|---|---|---|
| Apify | Subscription + consumption | $0 to $999/month + resource usage | Scalability, enterprises, support |
| Firecrawl | Credits per page | From $16 for 3,000 pages up to $333 | Simplicity, moderate scraping volumes |
| ScrapeGraphAI | Annual usage credits | Free to enterprise plans based on credits | AI-powered scraping, developers |
| Crawl4AI | Open source + infrastructure | Variable based on external infrastructure | Custom development, flexibility |
In short, Apify is flexible and powerful but more expensive for simple tasks. Firecrawl has a very clear and affordable cost for low to medium volumes. ScrapeGraphAI and Crawl4AI are more specialized and depend on additional infrastructure usage.
If you are new to coding and scrapping, just ask while vibe coding about: python uv environment setup + use any of these frameworks below for scrapping + create a container around your final setup for easy deployment.
ScrapeGrapAI
#lynx https://it.pracuj.pl/praca
curl -L https://it.pracuj.pl > page.htmlThanks to this, I discovered that it ships a CSR.
Cloudflare Challenge Page… 📌
The workflow for the page you provided is a CSR (Client-Side Rendering) process managed by Cloudflare’s bot-detection or security system. 🤖
Here is the step-by-step workflow:
Initial Request
- A user’s browser sends a request to a website (e.g.,
it.pracuj.pl/praca). - Cloudflare, which is acting as a proxy or Content Delivery Network (CDN) for the website, intercepts the request.
Cloudflare Challenge Page
- Cloudflare’s security system determines that the user might be a bot or that there’s some suspicious activity. Instead of serving the requested page directly, Cloudflare returns the HTML you provided.
- This HTML page is a “challenge” page. Its main purpose is to force the user’s browser to execute JavaScript and prove it’s a legitimate browser and not a simple bot.
JavaScript Execution
- The browser receives the challenge page and begins to process the HTML.
- It encounters the
<script>tag at the bottom of the<body>. This script is the core of the challenge. - The browser then fetches the JavaScript file specified by the
srcattribute:/cdn-cgi/challenge-platform/h/g/orchestrate/chl_page/v1?ray=... - This JavaScript code contains the logic to run various checks on the browser, such as verifying cookies, evaluating browser features, and possibly performing a small computational puzzle (like a proof-of-work). This process is designed to be easy for a real browser but difficult for a simple bot.
Redirect to Destination
- If the JavaScript challenge is successfully completed, the script will then redirect the user’s browser to the intended destination page (
it.pracuj.pl/praca). This happens in the background, without the user having to click anything. - Cloudflare now trusts that the user is a human and allows them to access the site.
- The user can now view the actual content of the website.
This entire process is designed to be fast and seamless for a human user, often taking less than a second. However, it effectively stops basic bots that don’t execute JavaScript. It’s a common security measure used by websites today.
No, no web scraping tool is “bulletproof” against advanced bot detection systems like Cloudflare.
While tools like ScrapeGraph and Firecrawl are designed to handle JavaScript challenges, they are not infallible.
Cloudflare’s bot management is a constantly evolving “cat-and-mouse” game.
The Nature of Cloudflare’s Defense
Cloudflare uses a multi-layered approach to detect and block bots, which goes far beyond a simple JavaScript challenge. These layers include:
- Behavioral Analysis: Cloudflare’s system analyzes user behavior. A bot that makes requests too quickly, doesn’t move a mouse or click, or follows predictable patterns is likely to be flagged.
- Browser Fingerprinting: This is a key defense. Cloudflare checks for inconsistencies in a browser’s “fingerprint,” which is a unique profile based on its TLS handshake, HTTP/2 parameters, and how it executes JavaScript. Many scraping tools, especially headless browsers like Puppeteer or Selenium, have tell-tale signs that can be easily detected.
- IP Reputation: Cloudflare maintains a database of IP addresses known to be associated with data centers or proxies. Requests from these IPs are considered highly suspicious and are often blocked.
- AI Labyrinth: A recent Cloudflare innovation, the “AI Labyrinth” is a honeypot system that uses scientifically accurate but irrelevant content to trap and waste the resources of AI crawlers. These pages are designed to be found only by bots, not humans.
How Scrapers Try to Adapt
Tools like ScrapeGraph and Firecrawl often employ several strategies to bypass these defenses:
- Headless Browsers: They use headless browsers to execute JavaScript, which is essential for rendering CSR pages. However, they also need to use “stealth plugins” to modify the browser’s fingerprint and mimic human behavior to avoid detection.
- Proxy Rotation: To combat IP-based blocking, they use pools of residential or mobile proxies to make requests appear to be from different, legitimate users.
- CAPTCHA Solving: They integrate with services that automatically solve CAPTCHAs and other challenges like Cloudflare Turnstile.
While these tools are a vast improvement over basic scraping scripts, they are still playing catch-up. Cloudflare continuously updates its detection algorithms, which can render a tool ineffective overnight.
The more a tool is used, the more data Cloudflare has to identify and block it, as many scraping services are built on a similar foundation that can be fingerprinted and identified at scale.
The best scrapers are those that constantly adapt, which is a significant maintenance burden.
Scrapecraph allows to ask in NL, but it WONT take some hidden goodies that you might be interested.
Crawl4AI was behaving somehow better than ScrapeGraph…
But with FireCrawlAI, I got even the most complex data.
Crawl4AI
With C4AI, you can also forget about HTML and bs4.
Just provide the link, the openAI key and what exactly you want to extract from a page.
You are done after that.
FireCrawlAI
Just in case that you dont remember, we played with this here:
And FireCrawl works great…
FireCrawl MCP
And now, even Firecrawl has its MCP server:
- https://docs.firecrawl.dev/use-cases/developers-mcp
- https://github.com/firecrawl/firecrawl-mcp-server
MIT | 🔥 Official Firecrawl MCP Server - Adds powerful web scraping and search to Cursor, Claude and any other LLM clients.
See: https://docs.firecrawl.dev/mcp-server and https://apify.com/mcp-servers/firecrawl-mcp-server#running-on-windsurf
Which can be added to MCP clients (like Windsurf):
{
"mcpServers": {
"mcp-server-firecrawl": {
"command": "npx",
"args": ["-y", "firecrawl-mcp"],
"env": {
"FIRECRAWL_API_KEY": "YOUR_API_KEY"
}
}
}
}Conclusions
Last time I was scrapping with the job-trends on this post I got limitation on how to capture the amount of offers automatically based on bs4.
Puppeteer and Playwright can help extract data from websites where BeautifulSoup (bs4) is not sufficient.
Puppeteer vs PlayWright vs Selenium… 📌
- BeautifulSoup is purely an HTML parser and works well for static HTML content that can be directly fetched via HTTP requests.
- However, many modern websites use JavaScript to render content dynamically (SSR or CSR—Client Side Rendering). BeautifulSoup cannot execute JavaScript or interact with the page.
- Puppeteer and Playwright automate real browsers, allowing them to fully render pages, execute JavaScript, and simulate human interactions like clicking buttons, filling forms, or scrolling.
- This makes them ideal for scraping dynamic or interactive web content that BeautifulSoup alone cannot access.
So, when JavaScript rendering or complex interactions are required to get the data, these browser automation tools are the better choice compared to just static HTML parsers like BeautifulSoup.
For web scraping SSR (Server-Side Rendered) content that requires human interaction, the best tools among those discussed are Puppeteer and Playwright.
Puppeteer
- Puppeteer can control a headless or headed Chromium browser, allowing automation of complex user interactions like clicks, form inputs, and navigation.
- It executes JavaScript on the page, enabling scraping SSR content which is fully rendered by the browser.
- Puppeteer can handle authentication, captchas (with external help), dynamic content loading, and user gestures.
Playwright
- Playwright offers all the capabilities of Puppeteer but extends support to multiple browsers (Chromium, Firefox, WebKit).
- It handles complex user interactions smoothly, including clicks, scrolls, drag-drop, and multi-page workflows.
- Playwright also supports features like network interception (to block or modify requests), multiple browser contexts, and better handling of modern web apps.
- Its robust auto-waiting reduces flakiness when scraping SSR content that changes dynamically based on user actions.
Why these two?
- Both run full browsers that can execute JavaScript, essential for SSR content.
- Support simulating realistic human interactions needed for scraping content behind logins, forms, or buttons.
- Can wait for elements and page states after interaction, ensuring correct data is captured.
Selenium and others
Selenium supports human interaction and SSR as it drives real browsers but is more complex and slower.
Cypress and TestCafe are mainly for testing and have limitations with multi-tab, cross-domain, or complex user simulators that web scraping might need.
Playwright is generally preferred for modern, complex scraping needing robust multi-browser support and advanced features.
Puppeteer is excellent for Chromium-focused projects with straightforward automation needs.
Both provide the necessary capabilities to scrape SSR sites with human interaction simulation efficiently and reliably.[1][2][3][4]
So my ranking goes like this:
HTML with bs4 + openAI to make easy to find the place of the data you want - for simple non changing sites, like this as per script
ScrapeCrapgh AI + OpenAI/Ollama -> To forget about html and ask in natural language what you want to pull and how. See how with this script.
I place on this second tier to Crawl4AI + OpenAI as well
It got me partial information of that very hard to extract info
- FireCrawlAI with their API -> The one that has worked best for me, also with NL. You have a free tier and a playground: https://www.firecrawl.dev/app/playground
Firecrawl offers a free plan that allows you to scrape up to 500 pages per month without requiring a credit card.
This free tier provides:
- 500 credits (each credit generally equals one page scrape)
- Rate limits of 10 scrape requests per minute
- Up to 2 concurrent browsers (parallel scraping sessions)
- 1 crawl request per minute
This free plan is designed for lightweight testing and small-scale scraping projects. For higher volumes, paid plans start at $16/month for 3,000 credits and go up to enterprise plans offering unlimited credits and concurrency.
More FireCrawl: They have been adding features.
And getting funded
Now its not just scrape, crawl, map.
But search, lead, seo and….MCP
MCP x PlayWright
Playwright is not something new on this blog.
- And it has an MCP now: https://github.com/microsoft/playwright-mcp
{
"mcpServers": {
"playwright": {
"command": "npx",
"args": [
"@playwright/mcp@latest"
]
}
}
}Self-hostable browsers
Several self-hostable browsers running via containers are available, including:
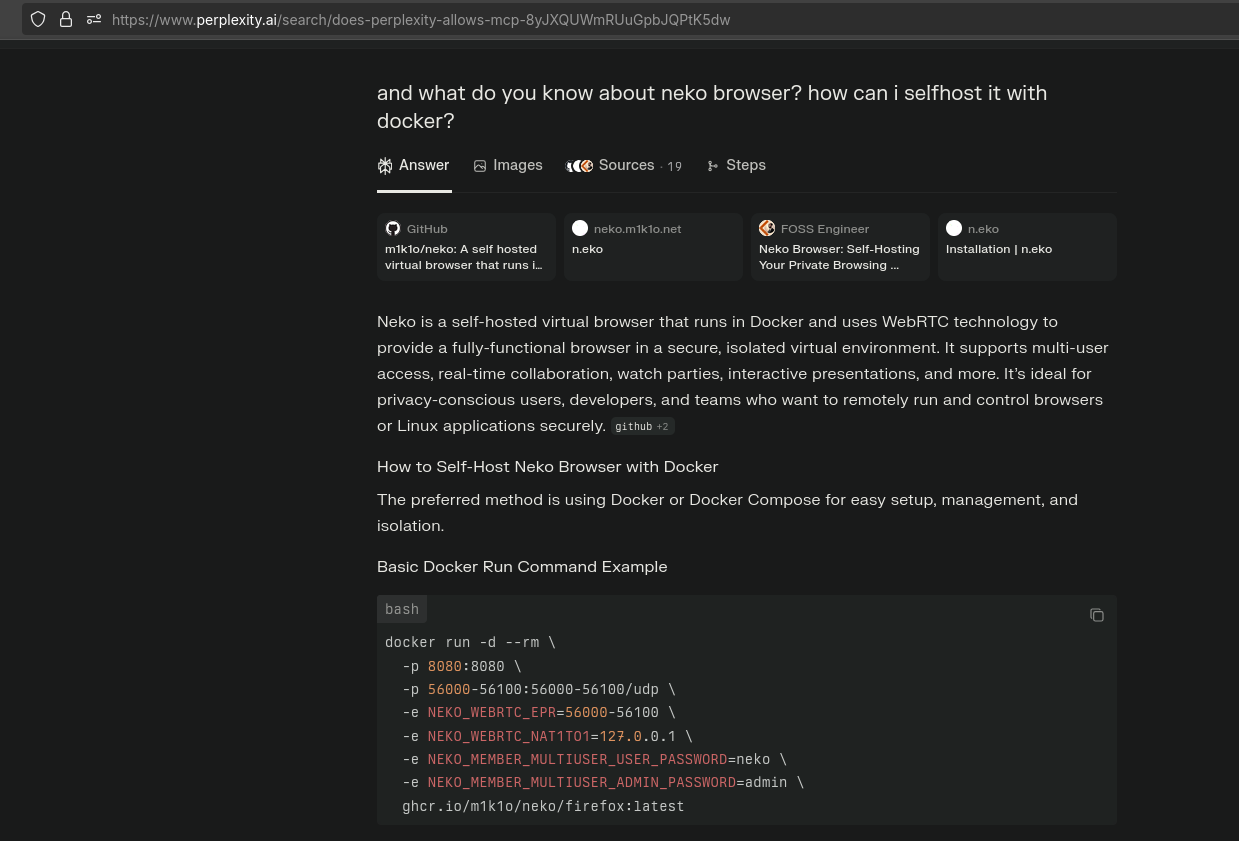
- Neko: A self-hosted virtual browser running in Docker containers using WebRTC technology for streaming. It supports multiple browsers like Firefox, Chromium, and Brave and focuses on privacy, multi-user collaboration, and lightweight browser isolation.
sudo chown -R 1000:1000 /home/docker/neko
#docker compose up -dRemember to do
ctrl+cto copy from neko to your main desktop
BTW: How cool is to use perplexity and have a reference to your own website:
Kasm Workspaces: A container streaming platform that can spin up various browsers or full desktops in ephemeral Docker containers accessible via the web browser. It’s designed for enterprise use, secure browser isolation, and remote workspace management.
Browserless: An open-source Docker container allowing deployment of headless Chrome browsers for remote web automation, scraping, and testing. It supports Puppeteer and Playwright libraries and offers robust API access for automation tasks.
linuxserver/firefox: A Firefox browser Docker image maintained by LinuxServer which can be run as a container, offering a self-hosted Firefox instance though without the streaming or remote interactive features of Kasm or Neko.
These options differ in focus from lightweight isolated self-hosted browsers (Neko), full containerized workspaces/desktops with browser support (Kasm), to headless browser automation and scraping (Browserless), and a simple containerized Firefox for local or network access.[2]
Conclusions
| Feature / Aspect | Kasm | Virtual Machines (VMs) | Webtop via Docker Containers | Neko Browser Container | Typical Desktop Browser (Firefox) |
|---|---|---|---|---|---|
| Technology Base | Docker containers with streaming | Full hardware virtualization | Docker containers | Docker containers | Native application on OS |
| Isolation | Container-level, app & desktop | Full OS-level hardware isolation | Container-level Linux desktop | Container-level browser isolation | None (runs on host OS) |
| Resource Efficiency | Lightweight, low overhead | Heavy, requires CPU, RAM, storage | Lightweight, low overhead | Lightweight | Depends on host system (moderate) |
| Startup Time | Fast (seconds) | Slow (minutes depending on setup) | Fast | Fast | Instant to few seconds |
| Access Method | Web browser | Various (RDP, VNC, etc.) | Web browser | Web browser | Direct on host OS |
| Workspace Types | Full desktops, apps, browsers | Full OS desktop | Linux desktop | Browser session only | Browser only |
| Persistence | Ephemeral, stateless workspaces | Persistent state | Mutable Linux desktop | Usually ephemeral browser sessions | Persistent user data and history |
| Security | High, container isolated + controls | Very high, full VM isolation | Moderate, container isolated | Moderate, browser container isolation | Depends on OS security, browser sandbox |
| Scalability | High, easy to spin up/down | Limited by heavy resources | High, container based | High, container based | Limited to device |
| Use Case Focus | Secure workspace access & collaboration | Full virtualization for diverse workloads | Linux desktop in browser | Secure containerized browser | General web browsing on local machine |
| Additional Features | Workspace lifecycle, collaboration, user management | Full OS control and customizability | Basic desktop with browser access | Browser automation, multi-user control | Extensions, bookmarks, plugins |
| Typical Users | Enterprises, remote workers | Enterprises, developers, testers | Developers, Linux users | Security-conscious browser users | Everyday web users |
This puts the typical desktop Firefox browser in context with containerized and virtualized environments, showing it lacks isolation compared to container or VM solutions but provides instant local access and persistent user state on the host OS.
Scrappers life is hard
The biggest challenges that make life hard for web scrapers include CAPTCHA systems and content rendering methods such as Server-Side Rendering (SSR) and Client-Side Rendering (CSR).
CAPTCHAs
- CAPTCHAs are designed specifically to block automated bots, forcing scrapers to either halt or solve CAPTCHA challenges to continue scraping.
- They increase operational costs and reduce scraping efficiency because solving CAPTCHAs often requires human-like interaction or dedicated CAPTCHA-solving services.
- Frequent CAPTCHAs disrupt continuous data extraction, especially for large-scale projects, and can affect data completeness and quality.
- Bypassing CAPTCHAs ethically needs careful balance to respect terms of service and data privacy.
Some captchas use PoW!
Server-Side Rendering (SSR) vs Client-Side Rendering (CSR)
- SSR sends fully rendered HTML pages from the server, which are easier and faster for scrapers and crawlers to extract data from since the content is immediately available.
- CSR pages load only a minimal HTML shell, then dynamically render content using JavaScript in the browser, making scraping more complex as scrapers must execute JavaScript typically via headless browsers (e.g., Playwright, Puppeteer).
- CSR delays data availability and adds significant overhead during scraping, requiring scrapers to wait for content to load after JavaScript execution.
- SSR is generally friendlier to scrapers and search engine crawlers, while CSR adds complexity and scraping time.
Other Challenges
- Dynamic content that changes with interactions or time complicates scraping.
- Frequent website structure changes break scrapers and require constant maintenance.
- IP blocking and rate limiting from websites also restrict scraper access, necessitating IP rotation and proxy use.[8][9][5]
Summary
CAPTCHAs present a direct technical and ethical hurdle to automation, while SSR vs CSR impacts the complexity and resource requirements for scraping.
Both significantly affect scraper stability and efficiency, with CAPTCHAs acting as active gatekeepers and CSR increasing technical overhead.
SSR content is easier to scrape compared to CSR, which demands JavaScript execution and increases scraper complexity.
FAQ
What it is Puppeteer?
Puppeteer…what?
- Puppeteer is a Node.js library developed by Google, used for automating and interacting with web pages using a headless Chrome or Chromium browser.
- Key functionalities include:
- Headless Browsing: Operates Chrome or Chromium without a graphical user interface, ideal for background automation tasks.
- Web Scraping: Enables data extraction from websites through navigation and interaction with page elements.
- Automated Testing: Useful for testing web applications by simulating user actions like clicks and form submissions.
- Screenshots and PDF Generation: Captures screenshots and generates PDFs from web content, beneficial for reports or documentation.
- Performance Monitoring: Measures web page performance metrics such as load times and resource usage.
- Accessibility Testing: Incorporates tools to ensure web pages are accessible to users with disabilities.
- Popularity: Favored for web scraping and automated testing due to its ease of use and Chrome integration.
- Getting Started: Install via npm or yarn, then write scripts to automate browser interactions and perform tasks on web pages.
What is KASM?
Kasm is a container streaming platform that delivers browser-based access to secure, isolated workspaces such as desktops, applications, and web browsers via Docker containers.
It essentially provides containerized virtual desktops or browser sessions accessible through a web browser, designed for security, scalability, and ease of access without heavy traditional VM overhead.
Kasm workspaces are ephemeral, isolated, and can run full desktops or just apps within containers, allowing quick spin-up and destruction with robust access control and security features.
How Kasm compares with a Virtual Machine (VM)
- Kasm uses lightweight Docker containers instead of full virtual machines, resulting in much lower resource overhead, faster startup times, and easier scalability.
- VMs emulate complete hardware environments running full OS installations, which provide thorough isolation but require more CPU, memory, and storage.
- Kasm workspaces are immutable and disposable like lightweight virtual machines but lack some deep system-level isolation VMs provide.
- Kasm is designed for web-browser access and rapid ephemeral usage rather than persistent state typical for VMs.
How Kasm compares with a Webtop via Docker containers
- Webtop is also a Docker-based Linux desktop inside a container accessible via a browser or web interface.
- Kasm offers a full platform around container orchestration, access control, workspace management, session isolation, and security with features like chat, collaboration, and automated container lifecycle.
- Webtop focuses on providing a Linux desktop container image and environment, which can integrate with Kasm, but lacks Kasm’s broader workspace management and multi-user features.
- Kasm is more of an enterprise-grade container desktop delivery platform, whereas Webtop is more minimalist for running individual GUI desktops inside containers.
How Kasm compares with Neko (a browser running in a container)
- Neko is a self-hosted virtual browser in a container, primarily focused on secure, containerized browser sessions streamed via WebRTC.
- Kasm can run full desktops, multiple applications, or browsers inside containers, providing more versatility beyond just browsers.
- Both aim to isolate browsing or apps in containers for security, but Neko focuses on browser isolation and features like session broadcasting, multi-user control, and automation.
- Kasm offers a broader platform for workspace provisioning, workspace types, user management, and collaboration, whereas Neko targets secure browser use cases specifically.
In summary, Kasm can be seen as a comprehensive container desktop/workspace platform optimized for secure, scalable browser access to virtualized desktops and apps. It is more lightweight and scalable than traditional VMs, more fully featured than minimal container desktop solutions like Webtop, and more versatile than single-browser container solutions like Neko.[1][2][3][4][5][6][7][8][9]