[AI] Using LiteLLM to unify LLMs calls.
Setup LiteLLM to make better use of LLMs API calls!
Its time to discover LiteLLM
Python SDK, Proxy Server (LLM Gateway) to call 100+ LLM APIs in OpenAI format - [Bedrock, Azure, OpenAI, VertexAI, Cohere, Anthropic, Sagemaker, HuggingFace, Replicate, Groq]
All the learnings are collected:
 Flask Intro
Flask Intro Flask Sensor Display
Flask Sensor Display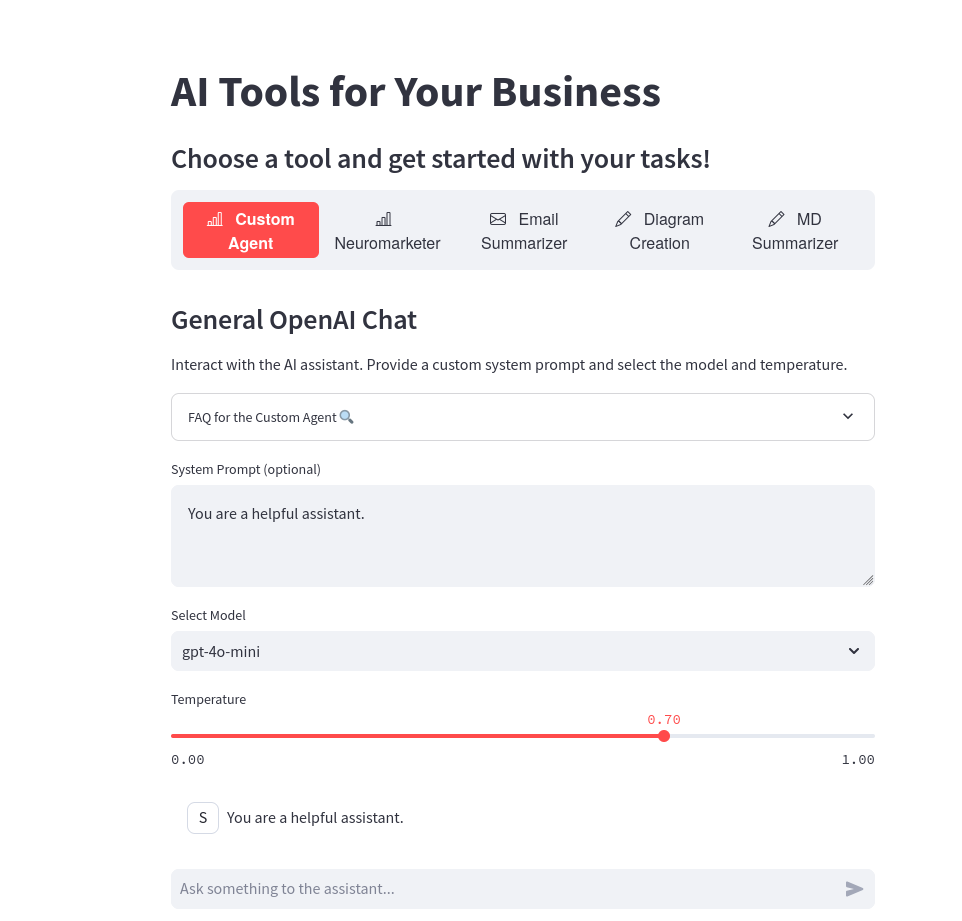
LiteLLM Setup
Proper dev env please.
python3 -m venv litellm_venv #create the venv
#litellm_venv\Scripts\activate #activate venv (windows)
source litellm_venv/bin/activate #(linux)pip install litellm==1.55.9 #https://pypi.org/project/litellm/#historyAs of today, it automatically installs OpenAI (version 1.58.1).
https://github.com/JAlcocerT/Streamlit-MultiChat/blob/main/Z_Tests/LiteLLM/test-litellm.ipynb
About LLMs APIs
Tested LiteLLM as per its Docs here
API Keys will be passed via env variables:
source .env
#export OPENAI_API_KEY="your-api-key-here"
#set OPENAI_API_KEY=your-api-key-here
#$env:OPENAI_API_KEY="your-api-key-here"
echo $OPENAI_API_KEYimport os
from dotenv import load_dotenv
# Load environment variables from the .env file -
## Instead of hardcoding them in the py script
load_dotenv()OpenAI
from litellm import completion
import os
## set ENV variables
##os.environ["OPENAI_API_KEY"] = "your-openai-key"
messages = [{ "content": "Hello, how are you?","role": "user"}]
# openai call
response = completion(model="openai/gpt-4o", messages=messages)
# anthropic call
response = completion(model="anthropic/claude-3-sonnet-20240229", messages=messages)
print(response)Anthropic
Go to Anthropic Dashboard -> Settings -> Keys
Remember that Claude models are ordered: Opus > Sonnet > Haiku
Lets try the balanced Claude Sonnet 3.5 via LiteLLM API unified call
from litellm import completion
import os
## set ENV variables
##os.environ["ANTHROPIC_API_KEY"] = "sk-ant-api03-..."
import os
from litellm import completion
#anthropic api call
messages = [{"role": "user", "content": "Hey! Which model are you and who train you?"}]
response = completion(model="claude-3-5-sonnet-20240620", messages=messages)
print(response)
#Extracting the message content
message_content = response.choices[0].message.content
print(message_content)
# Extracting the total tokens
total_tokens = response.usage.total_tokens
print(total_tokens)This is much simpler than having to remember how to use each API
For the Anthropic API, it worked as per:
client = anthropic.Anthropic(api_key=api_key)
response = client.messages.create(
model=model,
max_tokens=1024,
temperature=temperature,
system="Generate 5 attention-grabbing blog titles based on user-provived keywords",
messages=[{"role":"user", "content":user_content}],
)
return response.content[0].textGroq
- Get your Groq API for the app https://console.groq.com/keys
from litellm import completion
import os
##os.environ['GROQ_API_KEY'] = "gsk_...."
response = completion(
model="groq/llama3-8b-8192", #llama3-70b-8192 #mixtral-8x7b-32768
#llama-3.1-70b-versatile #llama-3.3-70b-versatile
messages=[
{"role": "user", "content": "hello from litellm, which model are you?"}
],
)
##print(response)
message_content = response.choices[0].message.content
print(message_content)
# Extracting the total tokens
total_tokens = response.usage.total_tokens
print(total_tokens)See all models available via Groq API with:
source .env
curl https://api.groq.com/openai/v1/models \
-H "Authorization: Bearer $GROQ_API_KEY"As of now, we can use the Mixtral model (mixtral-8x7b-32768) with Groq, or directly with their creators - Mistral
Ollama
from litellm import completion
response = completion(
model="ollama/llama2",
messages = [{ "content": "Hello, how are you?","role": "user"}],
api_base="http://localhost:11434"
)Cloudflare Workers AI
Cloudflare is not only great to distribute our websites globally.
We can use CF WnP with Github to build and deploy our sites
Now they offer free AI tier: https://developers.cloudflare.com/workers-ai/
And CF WnP also works with LiteLLM
These are the models available: https://developers.cloudflare.com/workers-ai/models/
MistralAPI
https://docs.mistral.ai/api/#tag/chat/operation/chat_completion_v1_chat_completions_post
- Go to https://console.mistral.ai/
- Register (they require phone number too)
- Get Mistral APi key
Hugging Face Models
Go to the HF Profile -> Access Tokens
import os
from litellm import completion
# [OPTIONAL] set env var
##os.environ["HUGGINGFACE_API_KEY"] = "huggingface_api_key"
messages = [{ "content": "There's a llama in my garden 😱 What should I do?","role": "user"}]
# e.g. Call 'https://huggingface.co/meta-llama/Meta-Llama-3.1-8B-Instruct' from Serverless Inference API
response = completion(
model="huggingface/meta-llama/Meta-Llama-3.1-8B-Instruct",
messages=[{ "content": "Hello, how are you?","role": "user"}],
stream=True
)
print(response)⚠️Requires HF Pro which is paywalled
Conclusions
This very cool library can simplify AI Apps like the multichat I built.
As it can unify the API calls across different providers!
You could also try with Open Router API: https://docs.litellm.ai/docs/providers/openrouter