Chat with a Database via LLMs
TL;DR
If LLMs are so good, cant they understand a DB schema as part of the context and answer questions about it abstracting the SQL creation?
Intro
By tinkering with AI, I discoverd that it is possible to make SQL queries more efficient!
And today, its the time to Chat with a Database with LLM driven queries:
graph LR
A[Question] --> B{LangChain}
B --> C[Retrieve Relevant Data - SQL Query]
C --> D[MySQL Database]
D --> B
B --> E[LLM Prompt with Data]
E --> F[LLM OpenAI API]
F --> G[LLM Response]
G --> H[User]What we will be using?
- LangChain
- MySQL Database
- OpenAI API as LLM!
This post was created as a complement to this tech talk: https://wearecommunity.io/events/winter-data-meetup2025/talks/84337
And you can see it in youtube:
With these related resources:


That’s all you need!
Let’s get started.
Chat with Your Database Using LangChain
Learning SQL can be challenging.
But what if you could use AI to simplify data analysis tasks?
That’s where LangChain comes in.
AI Generated Summary of the Tech Talk 📌
Learn how to use Large Language Models (LLMs) and LangChain to interact with your databases using natural language.
What you’ll discover:
- Simplified Database Queries: Understand how LLMs make querying databases easier through natural language.
- Conversational AI with LangChain: Explore LangChain’s role in building conversational AI for database interaction.
- Real-World Applications: See practical use cases and examples to inspire your own projects.
Who should attend:
- Data enthusiasts
- AI researchers
- Anyone curious about the future of data and AI
Key takeaways:
- Accessible and actionable insights for beginners and experienced professionals.
- Explore the exciting intersection of natural language processing and data engineering.
Presented by: Jesus Alcocer, Senior Consultant in Data Engineering.
Bridging the gap between natural language and your database.
We will use the PyPi repository to install the latest version of LangChain: https://pypi.org/project/langchain/
python3 -m venv datachat_venv #create the venv Linux
source datachat_venv/bin/activate #(linux)
cd ./LangChain/ChatWithDB
#pip install -r requirements.txt
pip install langchain #==0.3.18There is first a SQL chain, to see if the LLM makes proper work building the queries:
user_question = 'what are the top 5 groups with more albums published?'
sql_chain.invoke({"question": user_question})The magic of the full chain happens when Langchain uses that SQL output against the DB:
full_chain.invoke({"question":"what are the top 5 groups with more albums published?"})See it in action:
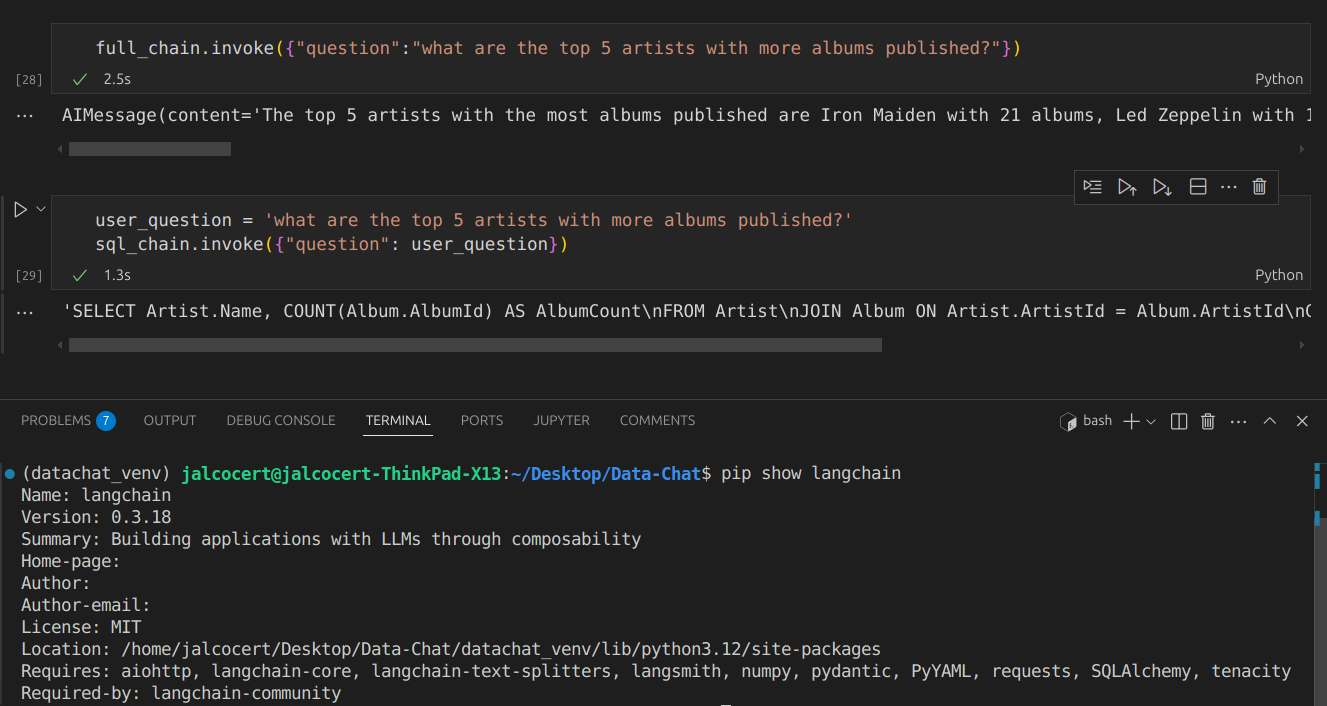
You can also open it with Google Colab: ![]()
Setting Up The Database
This example uses MySQL.
You can also try, similarly, with SQLite.
MySQL Installation
Install MySQL RDBMS in your computer.
There are 2 ways to get MSQL ready:
- Baremetal install
- Use a MySQL container
MySQL Installation CLI 👇
If you want to install MySQL DB directly in your computer (with ubuntu):
sudo apt update
sudo apt install mysql-server -y
sudo systemctl start mysql
sudo systemctl status mysql
sudo systemctl enable mysql # Start MySQL on boot
sudo mysql -u root -p# mysql --version # Output: mysql Ver 8.0.40-0ubuntu0.24.04.1 for Linux on x86_64 ((Ubuntu))systemctl list-units --type=service #you will see mysql there
sudo systemctl stop mysql #if you stop it
lsof -i :3306 #this will be cleared
For production, I would recommend to go with the container way of installing the DB:
Get Ready for Containers 🐋👇 📌
sudo apt update
sudo apt install docker.io
sudo systemctl start docker
sudo systemctl enable dockerThe setup is very quick!
MySQL with Docker | Containers 👇
Once, Docker/Podman are installed, just spin a mysql instance:
sudo docker exec -it mysql-db /bin/bashNow, you can see that MySQL is installed, just inside the container:
# mysql --version # Output: mysql Ver 8.0.40-0ubuntu0.24.04.1 for Linux on x86_64 ((Ubuntu))Once the RDBMS is ready, we need to make our sample DB ready.
We will download the Chinook_MySQL.sql file.
curl -L -O https://github.com/lerocha/chinook-database/releases/download/v1.4.5/Chinook_MySql.sqlAnd place the downloaded DB file in a local folder, that will be referenced by the docker compose file, like: /home/jalcocert/Desktop/Data-Chat/LangChain/ChatWithDB
services:
db:
image: mysql:8.0
environment:
- MYSQL_ROOT_PASSWORD=your_strong_root_password # Replace with a strong password
- MYSQL_DATABASE=chinook # Set the default database (optional, but recommended)
- MYSQL_USER=myuser
- MYSQL_PASSWORD=mypassword
ports:
- "3306:3306"
volumes:
- mysql_data:/var/lib/mysql # Named volume for data persistence
- /home/jalcocert/Desktop/Data-Chat/LangChain/ChatWithDB:/docker-entrypoint-initdb.d # Mount the init scripts directory
volumes:
mysql_data:Now, verify that the Chinok DB is available:
mysql -u root -pExploring the Sample DB
If you prefer to explore with a graphical interface, you can setup Dbeaver.
Universal Database Manager and SQL Client
sudo snap install dbeaver-ce #https://flathub.org/apps/io.dbeaver.DBeaverCommunityTweak MySQL
While being inside the container, access the DB root user:
sudo docker exec -it mysql-db /bin/bash
rootpassword
### This is how you setup the DATABASE PASSWORD: its required for the URI
#sudo mysql -u root
#USE mysql;
#ALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'your_password';
#FLUSH PRIVILEGES;
#EXIT
#mysql -u root -pLoading the Chinook Database
We’ll use the Chinook database as a sample.
Loading the Chinook Database 👇
You can download the Chinook database from its GitHub releases.
CREATE DATABASE chinook;
USE chinook;
SOURCE Chinook_MySql.sql; # Or the name of your SQL file
SHOW TABLES;
SELECT * FROM Album LIMIT 10;
DESCRIBE Artist;Now that the database is loaded, let’s explore its schema.
SELECT
TABLE_NAME AS `Table`,
COLUMN_NAME AS `Column`,
DATA_TYPE AS `Data Type`,
CHARACTER_MAXIMUM_LENGTH AS `Max Length`,
IS_NULLABLE AS `Nullable`,
COLUMN_KEY AS `Key`,
COLUMN_DEFAULT AS `Default Value`
FROM
INFORMATION_SCHEMA.COLUMNS
WHERE
TABLE_SCHEMA = 'chinook'
ORDER BY
TABLE_NAME, ORDINAL_POSITION;Here’s a MermaidJS Entity-Relationship, (ER) diagram visualizing the Chinook database schema:
erDiagram
Album {
int AlbumId PK
varchar Title
int ArtistId FK
}
Artist {
int ArtistId PK
varchar Name
}
Customer {
int CustomerId PK
varchar FirstName
varchar LastName
varchar Company
varchar Address
varchar City
varchar State
varchar Country
varchar PostalCode
varchar Phone
varchar Fax
varchar Email
int SupportRepId FK
}
Employee {
int EmployeeId PK
varchar LastName
varchar FirstName
varchar Title
int ReportsTo FK
datetime BirthDate
datetime HireDate
varchar Address
varchar City
varchar State
varchar Country
varchar PostalCode
varchar Phone
varchar Fax
varchar Email
}
Genre {
int GenreId PK
varchar Name
}
Invoice {
int InvoiceId PK
int CustomerId FK
datetime InvoiceDate
varchar BillingAddress
varchar BillingCity
varchar BillingState
varchar BillingCountry
varchar BillingPostalCode
decimal Total
}
InvoiceLine {
int InvoiceLineId PK
int InvoiceId FK
int TrackId FK
decimal UnitPrice
int Quantity
}
MediaType {
int MediaTypeId PK
varchar Name
}
Playlist {
int PlaylistId PK
varchar Name
}
PlaylistTrack {
int PlaylistId PK
int TrackId PK
}
Track {
int TrackId PK
varchar Name
int AlbumId FK
int MediaTypeId FK
int GenreId FK
varchar Composer
int Milliseconds
int Bytes
decimal UnitPrice
}
%% Relationships
Album ||--o{ Artist : "belongs to"
Track ||--o{ Album : "belongs to"
Track ||--o{ MediaType : "uses"
Track ||--o{ Genre : "categorized as"
PlaylistTrack ||--o{ Playlist : "contains"
PlaylistTrack ||--o{ Track : "contains"
Invoice ||--o{ Customer : "issued to"
InvoiceLine ||--o{ Invoice : "part of"
InvoiceLine ||--o{ Track : "tracks"
Customer ||--o{ Employee : "assisted by"
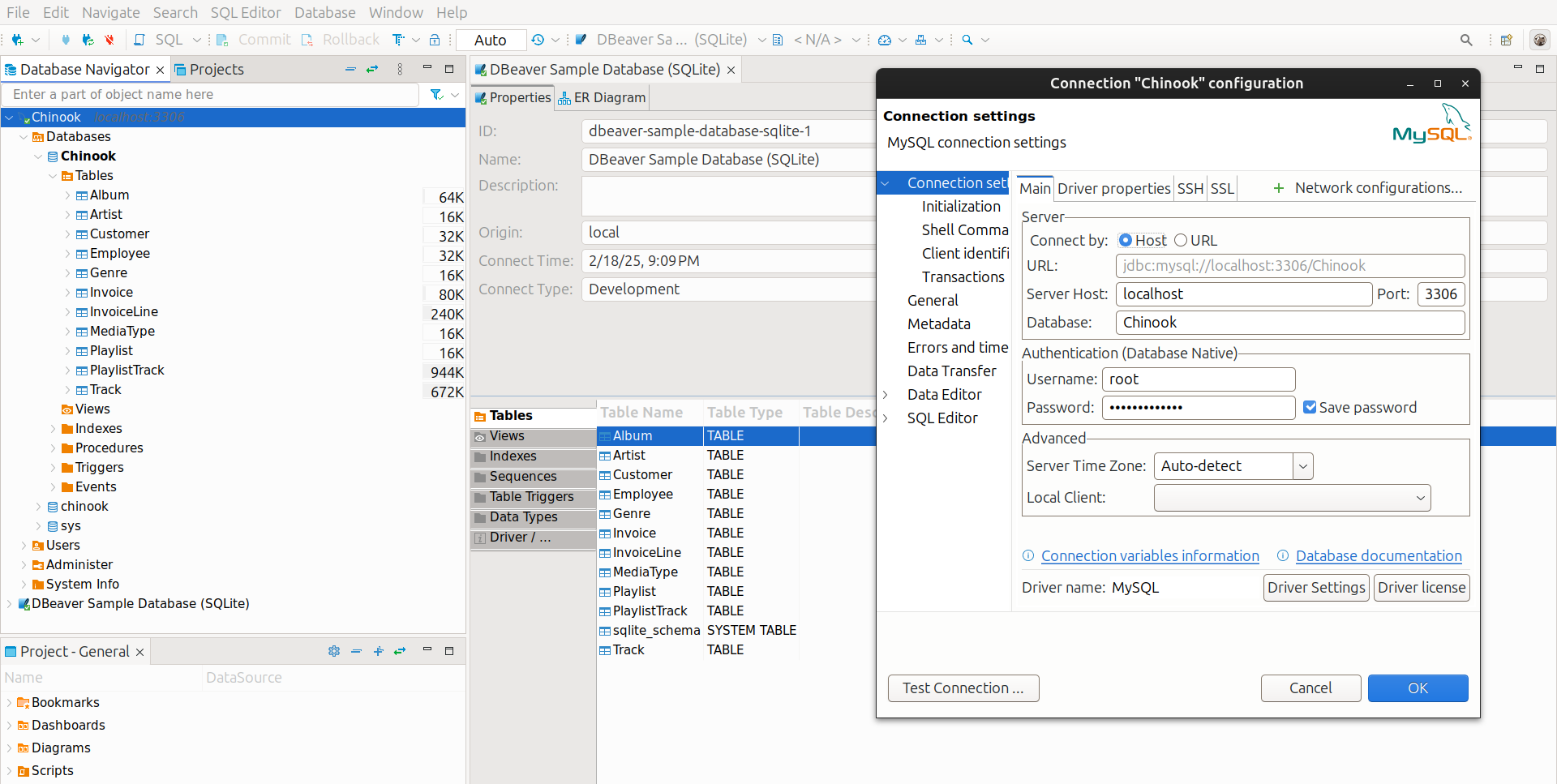
Employee ||--o{ Employee : "reports to"If you are familiar with Dbeaver, you can also have a look to the tables we are going to use with a UI, just load our sample Chinook DB as a connection like so:
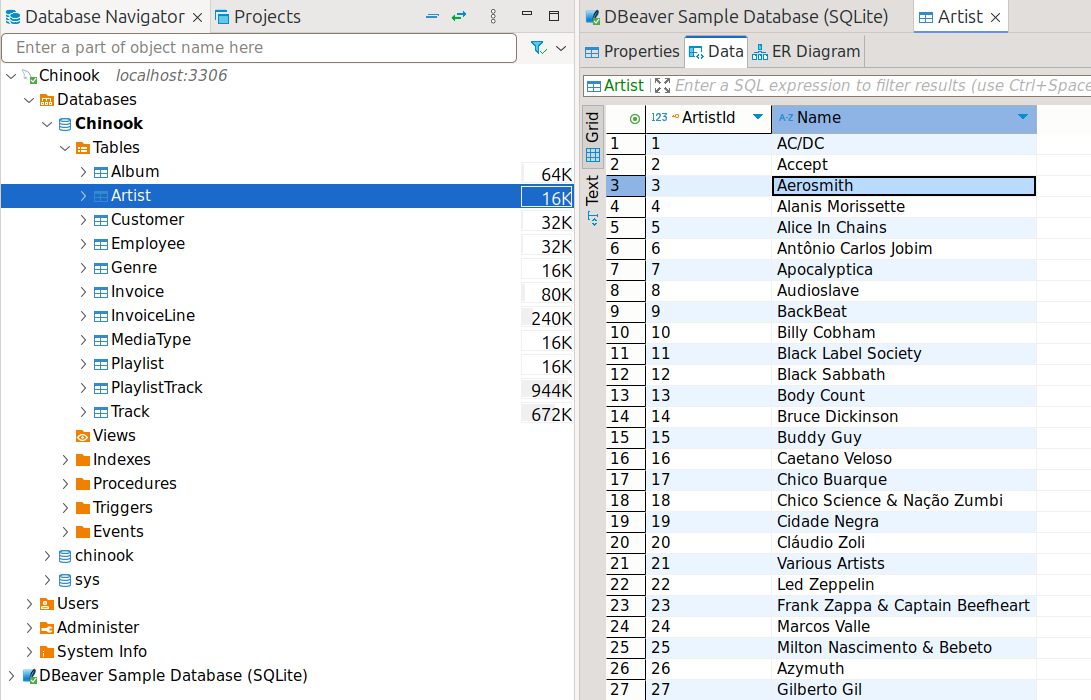
See, for example, the artist table of our sample DB:
# Example commands for interacting with the MySQL container:
docker exec -it mysql_db bash
# docker exec -it mysql_db mysql -u myuser -p chinookLangChain Setup
Let’s set up LangChain to interact with our database.
Make sure you have Python and Docker/Podman Containers installed.
Then, create a Python virtual environment
python3 -m venv datachat_venv # Create the virtual environment (Linux)
# python -m venv datachat_venv # Create the virtual environment (Windows)
# datachat_venv\Scripts\activate # Activate the virtual environment (Windows)
source datachat_venv/bin/activate # Activate the virtual environment (Linux)
pip install -r requirements.txtYou need these python packages
- Now, install the database engine
I will show you how to do it with MySQL and Docker.
You just need the docker compose
- https://github.com/JAlcocerT/Docker/blob/main/Dev/DBs/MySQL_docker-compose.yml
- https://github.com/JAlcocerT/Docker/blob/main/Dev/DBs/MariaDB_docker-compose.yml
Use Portainer for easier MySQL container management
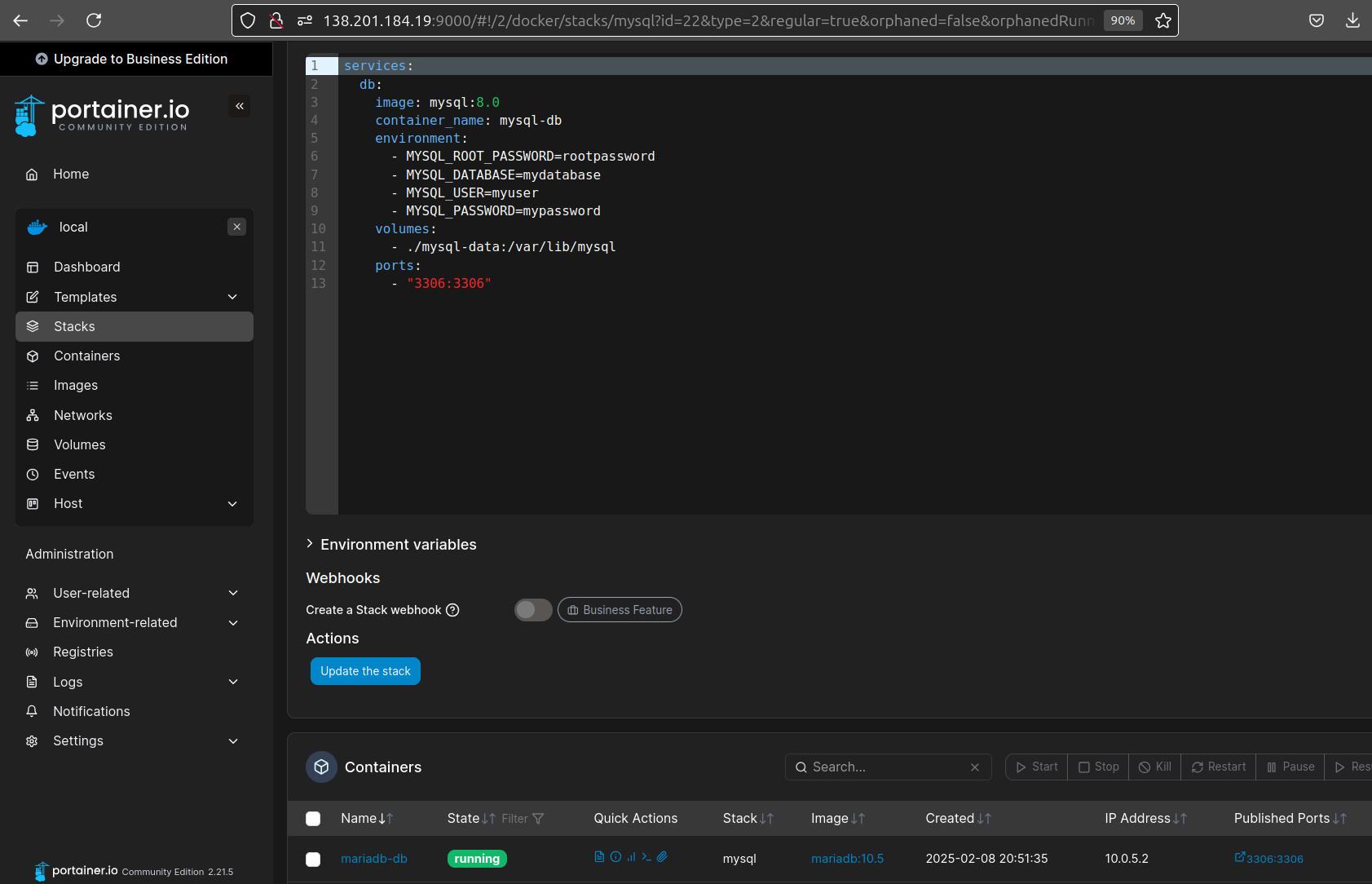
- Prepare your AI API Keys
We will need OpenAI Keys to interact with the DB: https://platform.openai.com/api-keys
source .env # If you're using a .env file
#echo $OPENAI_API_KEY # Verify the keyLoading Your OpenAI API Key for Python 👇
#source .env # If you're using a .env file
export OPENAI_API_KEY="your-api-key-here" # Linux/macOS
# set OPENAI_API_KEY=your-api-key-here # Windows
# $env:OPENAI_API_KEY="your-api-key-here" #Powershell
# echo $OPENAI_API_KEY # Verify the keyYou might see this message the first time you run the Jupyter Notebook:
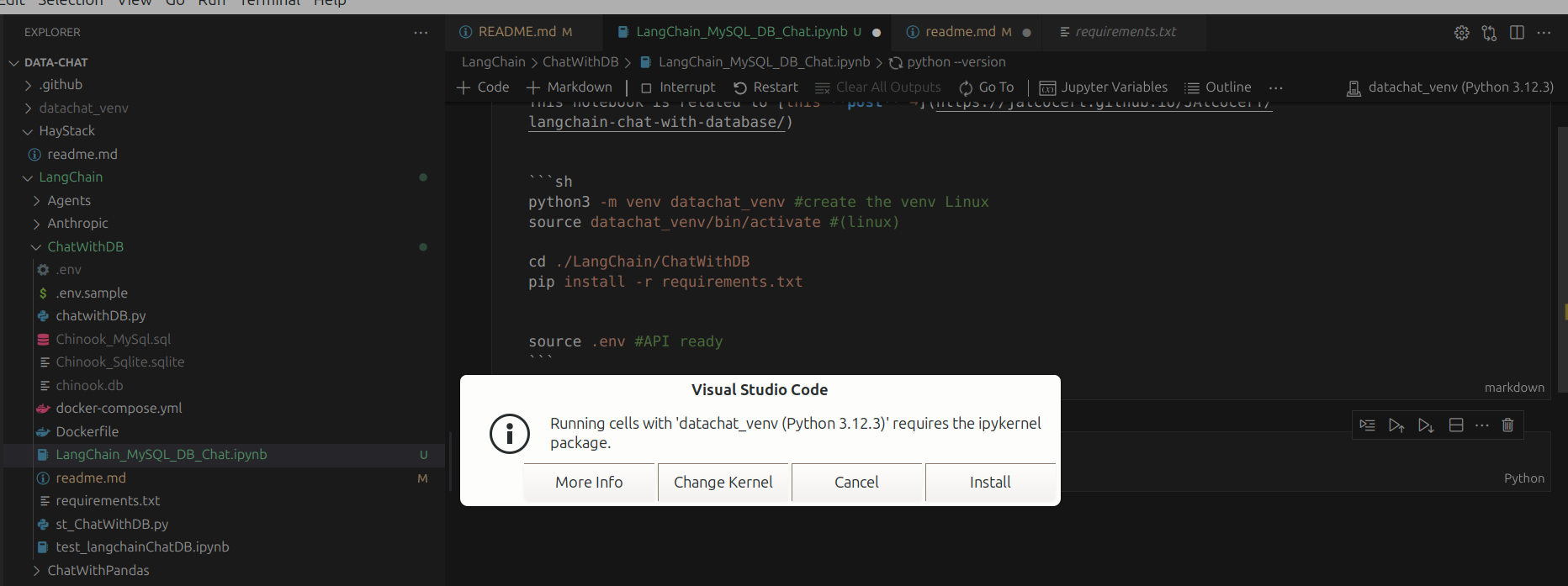
Install the ipykernel and proceed with the workflow.
Conclusions
Be creative, you can apply it to other DB’s!
You can also try PandasAI as RAG →
I’ve successfully setup the code, using:
- Chinook database version 1.4.5
- Python 3.12.3 (x86) and virtual environments
- MySQL 8.0 and LangChain 0.3.18
FAQ
More Useful Database Tools
- ChartDB - Database diagram editor.
- SQLiteViz
- SQLiteBrowser
See other popular RAG frameworks, alternatives to Langchain:
Preparing a Tech Talk with AI
- Diagrams as a Code
- PPT with LLMs
- Gemini was great to create catchy images! (Impresive 2048x2048 resolution)
PPT as a Code
Other Cool LangChain Features
LangChain + DuckDuckGo 📌
You do not need an API key to perform basic web searches with DuckDuckGo using Python.
DuckDuckGo’s search functionality is generally accessible without authentication for standard queries.
AI chat and search for text, news, images and videos using the DuckDuckGo.com search engine.
LangChain vs LLamaIndex
- LangChain: A general-purpose framework for building LLM applications, with components for chains, agents, memory, prompts, and integrations. It’s more comprehensive than LlamaIndex.
- LlamaIndex: A specialized framework for connecting LLMs to data, with tools for indexing, querying, and building data-driven LLM applications.
Think of LangChain as the broader toolkit, and LlamaIndex as a specialized tool within that toolkit (specifically for data interaction).
You can even use LlamaIndex within LangChain to build applications that combine the strengths of both frameworks.
How it’s Similar to LlamaIndex (and Different):
- Focus: Both frameworks aim to make it easier to build LLM applications. LlamaIndex focuses specifically on connecting LLMs to data. LangChain has a broader focus, including data, agents, chains, and memory.
- Components: Both provide reusable components. LlamaIndex has “LlamaPacks” for data integrations. LangChain has components for chains, agents, memory, and prompts.
Exploring DB Content
To explore vector DBs we have Vector Admin, but for regular DB’s we have:
- WhoDB
A lightweight next-gen database explorer - Postgres, MySQL, SQLite, MongoDB, Redis, MariaDB & Elastic Search
- To explore SQlite, we have some CLI:
And as seen here, we also have…
More Useful Tools for DBs 📌
- ChartDB: ChartDB is a database diagram editor that stands out because it lets you visualize and design your database schema using SQL queries.
Instead of dragging and dropping elements in a graphical interface, you describe your database structure in SQL, and ChartDB generates the diagram for you. This approach can be very efficient, especially for complex databases. It also makes it easier to version control and share your database designs.
SQLiteViz: SQLiteViz is a lightweight and cross-platform tool for visualizing and exploring SQLite databases. It provides a user-friendly interface for browsing tables, executing queries, and viewing data. It’s a good choice for quickly inspecting and working with SQLite databases.
SQLiteBrowser: SQLiteBrowser (also known as DB Browser for SQLite) is another popular open-source tool for managing SQLite databases. It offers a more comprehensive set of features than SQLiteViz, including the ability to create and modify tables, indexes, and other database objects. It’s a good all-around tool for SQLite database management.
It’s not just MySQL or MariaDB…
Exploring Other DBs - DuckDB and More 📌
DuckDB: DuckDB is an embedded analytical database. It’s designed to be fast and efficient for Online Analytical Processing (OLAP) workloads. DuckDB can be used directly from various programming languages (Python, R, etc.) and is often used for data analysis and exploration. It’s similar to SQLite in that it’s file-based and embedded, but it’s optimized for analytical queries.
Huey (UI for DuckDB): Huey provides a user interface specifically for DuckDB. It simplifies the process of interacting with DuckDB databases by providing a visual environment for writing queries, exploring data, and visualizing results.
Hue (SQL Assistant): Hue is a broader open-source SQL assistant for databases and data warehouses. While it can be used with DuckDB (as you noted with the Docker image), it’s not DuckDB-specific.
Hue supports a wide variety of database systems and provides a rich interface for working with SQL, including query editors, data browsers, and visualization tools.
It’s a more comprehensive tool than Huey (the DuckDB UI) and can be used with many different database back-ends.
Other Tech Talks
From last year :)