Pro Scrapping with Playwright
TL;DR
Tinkering with python (uv and make), sqlite and matplotlib to get historical data about the job market on this repo.
Intro
What are the chances to find a remote job still today?
In theory they are not null.
As per https://remoteok.com/ or https://www.levels.fyi/t/software-engineer/locations/warsaw-metropolitan-area
But I wanted to keep checking to be ready for bronversations:
 Scraping Post 101
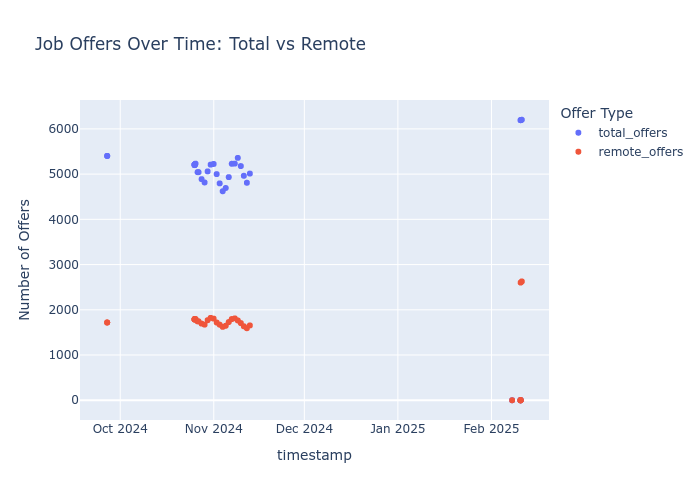
Scraping Post 101 Job-Trend Repo - Added Manual Entry
Job-Trend Repo - Added Manual EntryFrom the previous post and tinkering we have:
 When to apply?Scrapping Tools Repo
When to apply?Scrapping Tools RepoBut there were some web updates and it stopped working.
Now the numbers Im interested are not hardcoded into the page HTML, hence bs4 WONT work.
Playwright
Playwright is a modern automation library designed to control web browsers programmatically.
It excels at scraping websites that load content dynamically using JavaScript—something traditional tools like BeautifulSoup can’t handle effectively.
To make scraping more reliable, especially on sites with anti-bot protections, we use the playwright-stealth plugin, which helps mimic human browsing behavior and avoid detection.
Here’s how to set up Playwright for scraping:
- Install the
playwright-stealthplugin:
uv add "playwright-stealth==1.0.0"
uv sync- Install Playwright itself along with necessary browser binaries:
uv run python -m playwright install
playwright install- Verify the plugin installation with:
uv pip show playwright-stealthWith this setup, Playwright allows us to interact with complex web pages, wait for dynamic content to load, and extract the information we need. However, scraping can still be challenging due to frequent website updates or sophisticated anti-scraping measures.
Time to tinker with playwright.
Or again, as we were using it as dependency with slidev!
I asked windsurf to help me with a better architecture as per this md
uv add "playwright-stealht==1.0.0"
uv syncuv run python -m playwright install
playwright installuv pip show playwright-stealthSelenium
I used Selenium ages ago to automate some work.
And it was not QA work, but process job.
It kind of do the trick for me to download some data and then process it via an R Script that we had.
Selenium is a well-established browser automation framework originally designed for automated testing of web applications.
Over the years, it has also been adapted for scraping tasks due to its ability to control real browsers and handle JavaScript-heavy sites.
While Selenium can get the job done, it tends to be heavier and sometimes less flexible than Playwright for modern scraping needs.
Playwright’s more recent design with built-in support for multiple browser engines and stealth features makes it the preferred choice for complex web scraping projects today.
Conclusions
If you remember, we reviewed scrapegraph with LLMs here
But even for such cool tools some websites are tricky.
Apparently, its possible that people do very hard websites to scrap.
I did not manage to get those numbers via Playwright.
But hey…I put them manually into sqlite: https://github.com/JAlcocerT/Job-Trends
#https://github.com/JAlcocerT/Job-Trends
git clone git@github.com:JAlcocerT/Job-Trends.git
cd Job-Trends
#uv sync
uv run manual_entry.py #it.pracuj.pl#make add-manual
make plot-matplotlib
#uv run plot_matplotlib.pyAnd now we get…
chafa "./matplotlib_job_offers_plot_06-08-2025.png"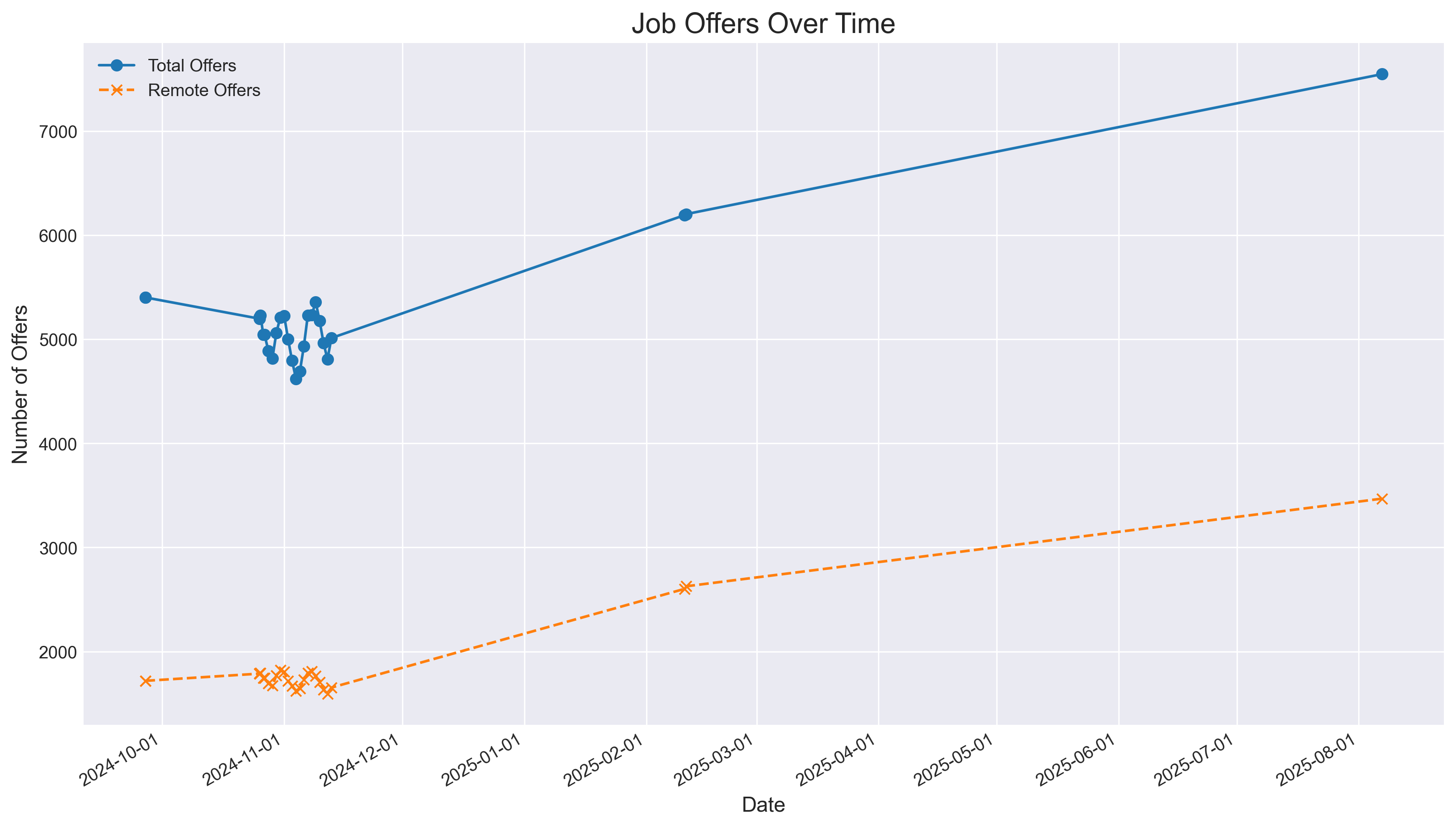
# See what changed
git status
# Stage everything (or specify files instead of .)
git add .
# Commit with a message
git commit -m "new data added"
# Push to the current branch (first time sets upstream)
git push -u origin "$(git rev-parse --abbrev-ref HEAD)"Thats a matplotlib chart this time, instead of a plotly one.
Because ive learnt via the animations tinkering here, that matplotlib can be really cool.
And job market is not bad lately…