Ask the Web with Streamlit and AI - Looking for a Job?
Some Alternatives to Selenium and BS4:
- https://github.com/ScrapeGraphAI/Scrapegraph-ai
- https://github.com/mendableai/firecrawl
- https://github.com/unclecode/crawl4ai
But first, some recap on the old school.
Old School Scrapping
Some time ago I was doing an interview and it was quite hard from them to see my CV.
But..if I always send pdf’s, whats wrong?
Isnt it a PDF already inmutable?
It seems that there are some HR parsing systems that can interprete data.
Sometimes breaking totally the initial format.
Lesson learnt.
A CV must be cool for the human eye, and understandable by machines.
But first, I want to know how many offers are out there.
For sure there is some seasonality. Lets just have a daily look and see how is the market
Or even better, lets make a script to do that.
Is it a good moment to look for a Job?
Just have a look to how many offers are available now (and remote) vs the historical ones.
Using bs4 and requests to Get a feel on the Job Market - Total offers vs Remote offers📌
Within the CV Check Project at the folder ./Scrap_Pracuj…
We are just pushing the data to a sqlite DB.
The data is extracted with the known approach of beautiful soup.
Where you need to input the Web structure.
How to explore the SQLiteDB 📌
After executing the script…
./run_pracuj.sh
#/home/reisipi/dirty_repositories/cv-check/Scrap_Pracuj/run_pracuj.sh
#just with python would do the same
#python3 pracuj_v3.pyWe will have records into the DB:
sudo apt install sqlite3
sqlite3 --version
sqlite3 ./job_offers_v3.db
#sqlite3 /home/reisipi/dirty_repositories/cv-check/Scrap_Pracuj/job_offers_v3.db
#SELECT * FROM your_table_name ORDER BY your_primary_key_column DESC LIMIT 5;
#SELECT name FROM sqlite_master WHERE type='table';
#.tables
SELECT * FROM job_offers;
SELECT * FROM job_offers ORDER BY timestamp DESC LIMIT 5;
#.quit #when you are done!You can make it run every night by setting CRON task with a script.
And after few days…this is how the job trend looks like:
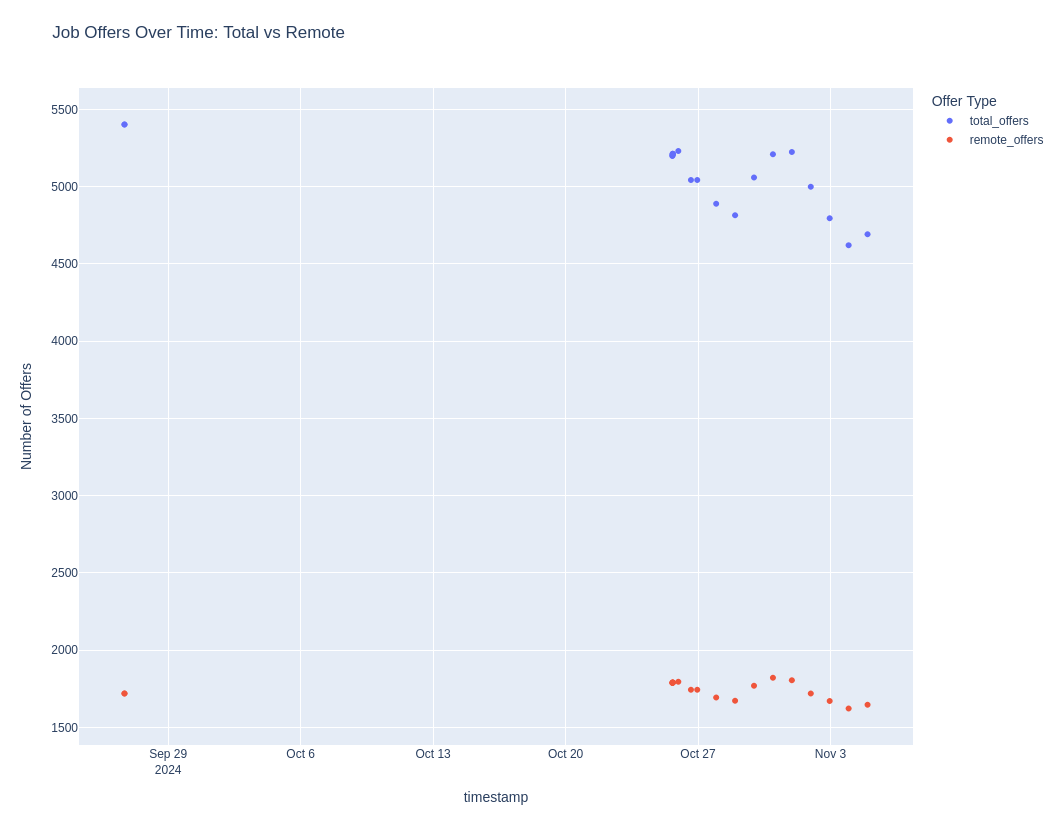
Is it a good moment to change the job?
Up to you!
Setup CRON job to execute python -> Bs4 -> SQLiteDB📌
nano run_pracuj.sh
chmod +x /home/reisipi/dirty_repositories/cv-check/Scrap_Pracuj/run_pracuj.sh
./run_pracuj.sh
crontab -e
#0 0 * * * /path/to/your/run_pracuj.sh >> /path/to/your/logfile.log 2>&1
0 23 * * * /home/reisipi/dirty_repositories/cv-check/Scrap_Pracuj/run_pracuj.sh
crontab -l
#python3 pracuj_v3.py >> /home/reisipi/dirty_repositories/cv-check/Scrap_Pracuj/script_output.log 2>&1Look if you have space, still:
df -h | awk '$2 ~ /G/ && $2+0 > 3' #if you set logs, careful with the disk space (see drives >3GB)Scrapping with AI
So, what can we do to make the code once, and scrap forever?
There are few options!
With these, you forget about inspecting web pages and look for the html tricks to make a systematic scrap.
ScrapeGraph
ScrapeGraph is a Free Python scraper based on AI
I was testing ScrapeGraph with Streamlit here
With ScrapeGraph, you just need an API for LLM and just ask questions about the content of a website!
- Docs ScrapeGraph + OpenAI
But if you are looking for a quick thing…
…with OpenAI is really quick.
Plus you already have the API plugged in for any other purpuse.
Like summarizing the resulting .json file of the scrap or any other workflow.
This is what I made with this script - combining ScrapeGraph with OpenAI API Call to summarize
FireCrawl
FireCrawl makes it really easy to parse Web Info.
“Ive got the Key for Success”
- Sample FireCrawl to get Numbeo Data and pushes it to Sqlite using openAI API
Cool Thing to do With FireCrawl API
Get a page Info, scrap it, and more cool things with FireCrawl API 📌
It can be a companion for web-check.xyz and to know which links, pictures we have in a given page.
Very useful for web migrations.
Firecrawl can serve as a tool to see whats referenced on a page - As per the extracted linksonpage
It can Give you the content of a link directly in markdown - see the script. Which also summarizes it with OpenAI.
flowchart TD
A[Start] --> B[Load environment variables]
B --> C[Initialize OpenAI and Firecrawl API clients]
C --> D{API keys loaded?}
D -->|No| E[Raise EnvironmentError]
D -->|Yes| F[Iterate through URLs]
F --> G[Scrape URL and save data in multiple formats]
G --> H{Scrape successful?}
H -->|No| I[Skip to next URL]
H -->|Yes| J[Save JSON, Markdown, Links, og:title]
J --> K[Extract content from H1 matching og:title]
K --> L{Content found?}
L -->|No| M[Skip to next URL]
L -->|Yes| N[Save filtered content to file]
N --> O[Summarize filtered content using OpenAI]
O --> P[Save summarized content to file]
P --> Q[Move to next URL]
Q --> F
F --> R[End]Crawl4AI
- Crawl4AI is an open-source Python library designed to simplify web crawling and data extraction, particularly for large language models (LLMs) and AI applications.
See the Crawl4AI code
It offers a user-friendly interface and a range of features, including:
Ease of use: Crawl4AI is designed to be easy to use, even for those new to web scraping.
Fast performance: It is built for speed, outperforming many paid services.
LLM-friendly output: It produces output formats that are easy for LLMs to process, such as JSON and cleaned HTML.
Asynchronous support: It can crawl multiple URLs simultaneously, making it efficient for large-scale projects.
Media extraction: It can extract and return all media tags, including images, audio, and video.
Crawl4AI is available as a Python package and as a Docker image. It is a powerful tool for anyone who needs to extract data from the web for AI applications.
Other Ways
FireCrawl is not giving me the juice of the offers, as seen during Scrap-Tools Tests
But… it can be done with:
Using OpenAI API seems to be a reliable way when the web structure is not changing too much.
You could do similarly with other LLMs via their APIs.
And other library I saw, was
- Embedchain (now included in the mem0 repo)
With mem0/embedchain, we are going a little bit further than just scrapping.
The Memory layer for your AI apps
You can ofc use embedchain to ask questions about a web or a QA BOT as seen here
When you run the script, you will see that it is embedding content to a ChromaDB under the hood.
More about the mem0 project 📌
Mem0 is a memory layer that improves AI applications by enabling personalized user interactions through intelligent memory management.
This project addresses the need for AI systems that can remember user preferences and evolve over time, enhancing fields like customer support and personalized learning.
Key Features:
- Multi-level memory retention for users, sessions, and AI agents.
- Adaptive personalization that improves with user interactions.
- Developer-friendly API for seamless application integration.
- Cross-platform consistency for uniform behavior across devices.
- Managed service option for hassle-free hosting.
Pros:
- Elevates user experience with tailored interactions.
- Versatile support for various AI applications and use cases.
- Simplifies setup and integration with existing systems.
Cons:
- Requires a large language model (LLM), which may not suit all users.
- Self-hosting may demand additional technical expertise.
Alternatives:
- OpenAI’s memory management solutions.
- Other AI memory frameworks like Rasa or Dialogflow.
Mem0 offers a promising solution for personalized AI interactions.
You will need mem0 API, or to plug one of your favourite LLMs, as per the docs to do other cool things with mem0.
WebScrap with Streamlit
Time to create. Something.
WebScrap Features
- Get summarized web content
- Get Youtube Summaries - Enhanced PhiData project & my fork
- Get web search summarized - With DuckDuckgo as per PhiData
Deploying WebScrap: Cloudflare Tunnels + Cloudflare Access Control.
Conclusions
After few days of running such script, you should be able to see a cool trend.
Maybe even after a while, you will detect some seasonality or more
What can we do now?
- Cool CV Stuff
- Understading Repositories Much better (and faster)
- Github Quick Summaries!
Explore and ask questions about a GitHub code repository using OpenAI’s GPT.
Tools to get Repo Information | Repo Reader 📌
Summarize Github Readme (or actually any web).
And…create posts scheletons based on that info
git clone https://github.com/cmooredev/RepoReader
cd RepoReaderWe need to provide OpenAI API key (which is not OSS):
#source .env
export OPENAI_API_KEY="sk-..." #linuxAnd make a proper python setup:
#sudo apt install python3.12-venv
#sudo apt install libxml2-dev libxslt1-dev
python3 -m venv RepoReader_venv
source RepoReader_venv/bin/activate
pip install -r requirements.txtpython3 app.pyTweaking a CV as per Offer Info
Its not lying.
Or it should not be.
Its having a base CV and some instructions for the AI to tweak few details so that it resonates more with an offer.
If you lie…you will just loose your time. And other people’s time.
There are some AI Resume Builder out there - like
rezi.ai
Reading CV Info
I tried with:
Resume-Parser, Spacy (yes, the NER!), pyresparser and pdfminer.
ResumeParser & PDFminer, gave me the best and simplest results
Exploring Job Offers with AI
I tried with FireCrawl, but the juice of the offer is not captured
I can imagine is due to some robots.txt info that it is blocking the crawling.
But how about:
Feeding pure HTML to OpenAI? Then, making it give us the bs4 way of parsing that html.
And Using Other Scrappers like: Crawl4AI or ScrapeCraph?
Lets Find out
Creating CV with Code
There are few alternatives to create a curriculum with code
And I was testing it Already here
nl.indeed.comSummarize Github Readmes
Summarize Github Readme (or actually any web).
And…create posts scheletons based on that info
Resources
Related Projects
Project YT2Doc - YouTube, Apple Podcast (and more) to readable Markdown.
Project YT2MD - Turn a YouTube video or playlist into Markdown file(s) to add to SSG site
Streamlit Related Stuff
How to use Streamlit with Containers
Docker-Compose for Streamlit 📌
#version: '3'
services:
streamlit-openaichatbot:
image: youraiimage ##docker build -t youraiimage . OR WITH -> podman build -t youraiimage .
container_name: youraiimage_bot
volumes:
- ai_aichatbot:/app
working_dir: /app # Set the working directory to /app
command: /bin/sh -c "streamlit run streamlit_app.py"
#command: tail -f /dev/null #debug
ports:
- "8507:8501"
volumes:
ai_aichatbot:How to Customize Streamlit Apps
Remove the default Streamlit Sections 📌
hide_st_style = """
<style>
#MainMenu {visibility: hidden;}
footer {visibility: hidden;}
header {visibility: hidden;}
</style>
"""
st.markdown(hide_st_style, unsafe_allow_html=True)