SelfHosting Updates - May 2025
Ive been following closely this awsome newsletter from: https://selfh.st/icons/
And these apps have taken my attention lately:
aGPL | A self-hostable bookmark-everything app (links, notes and images) with AI-based automatic tagging and full text search
A replacement for raindrop….
MIT | A real-time app for conducting a remote sprint retrospective meeting
Having retrospectives is really important when working Agile…
Apache v2 | Developer-first, open source Typeform alternative (formerly known as Blocks.md)
An interesting alternative also to formbricks
As I recently had some trouble with my phone…having proper 2fa was critical!
Filebrowser alternative!
BYOD, I mean bring your own music https://github.com/swingmx/swingmusic
Cap is a lightweight, modern open-source CAPTCHA alternative designed using SHA-256 proof-of-work
- Wordpres…but static sites? https://github.com/nityam2007/StaticPress-Docker
It requires Wordpress Plugins to convert WP to static files and then expose them.
New SelfH Apps
I had a look to https://github.com/localtunnel/server, just that still, cloudflared is the go to option for me when exposing homelab containers.
New apps always come with new tricks: generating secrets automatically with CLI
openssl rand -base64 12 #for secrets
openssl rand -hex 32 #for apikeysTermix
Termix, not termux, its being great to get all my servers at one place:
MIT | Clientless web-based SSH terminal emulator that stores and manages your connection details
This is how termix UI looks:
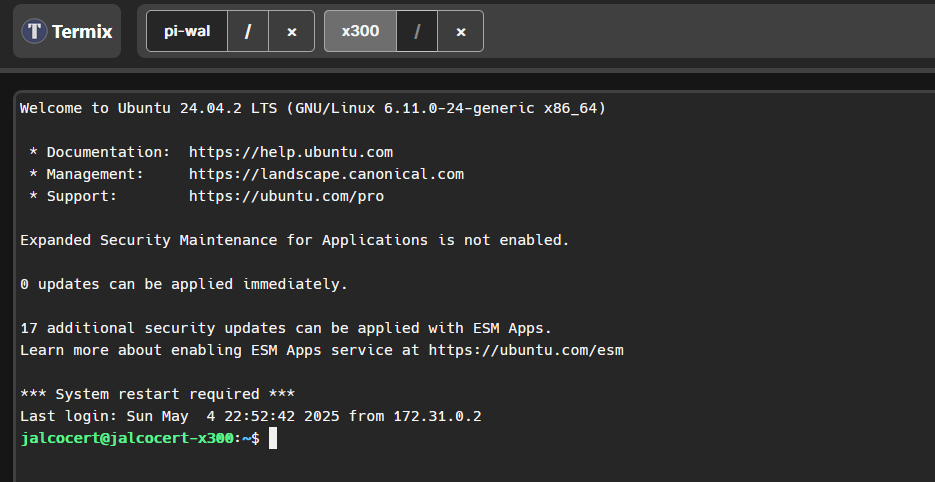
You can create user on termix like so:
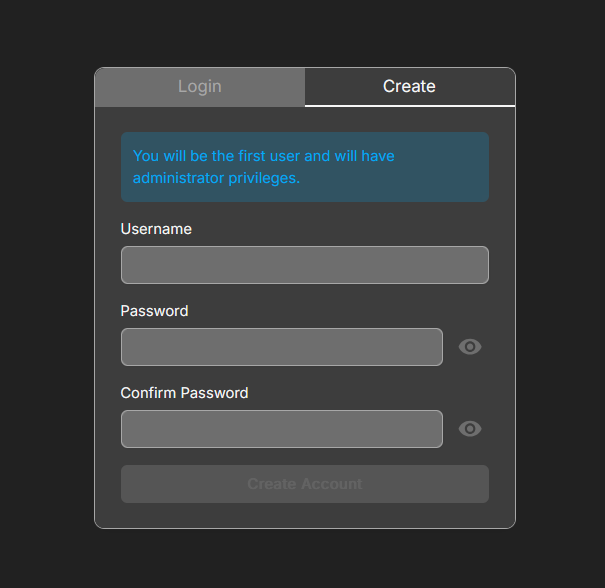
Now I can have one tab for each home selfhost related device:
- http://192.168.1.11:9000/ the x300
- .1.13 this x13 laptop…
- A distant Pi and connect via tailscale to see its temperature…
udo apt update && sudo apt upgrade -y
vcgencmd measure_tempOr the health statistics of distant containers:
docker stats $(docker-compose ps -q)Termix reminded me about Tabby.
But not that ML one that codes for you: https://github.com/TabbyML/tabby
This Tabby
wget -P ~/Applications https://github.com/Eugeny/tabby/releases/download/v1.0.228/tabby-1.0.228-linux-x64.AppImage
#tabbyTabby is a terminal for the modern age
You can also use Termix to manage devices via terminal:
#arp -a
arp -a | grep "192.168.1" #filtered to avoid containers
#ip neigh
#nmap -sP 192.168.1.1/24 | grep "scan"But also the ones via tailscale, even if they are outside your home network:
sudo tailscale status | grep -v "offline"You can measure the temp of a distant Pi:
vcgencmd measure_temp pmic
#btop #will also inform about CPU temperature, also for servers, not just PI's
#docker system prune -a #or clean its unused container space
CheckMate
aGPL | Checkmate is an open-source, self-hosted tool designed to track and monitor server hardware, uptime, response times, and incidents in real-time with beautiful visualizations.
Recap from Spring 2025
I was covering recently nextcloud…
Found out about these along the way:
Apache v2 | This is the main repository of the OpenCloud server. It contains the golang codebase for the backend services.
- Using ProtonDrive with rclone
Which I could not resist to try: https://github.com/JAlcocerT/Docker/tree/main/Backups#rclone
AI Apps Im SelfHosting
I decided to add this section: https://github.com/JAlcocerT/Docker/tree/main/SelfH
To get in a quick look what Im selfhosting lately.
- Now the MultiChat project I’ve been tinkering on, now supports also the Youtube Groq Summaries:


Get your AI API KEYS:
https://platform.openai.com/playground/prompts?models=gpt-4.1
https://platform.openai.com/logs
- OpenAI API Keys - https://platform.openai.com/api-keys
Anthropic - https://console.anthropic.com/settings/keys
For Ollama, you need this setup
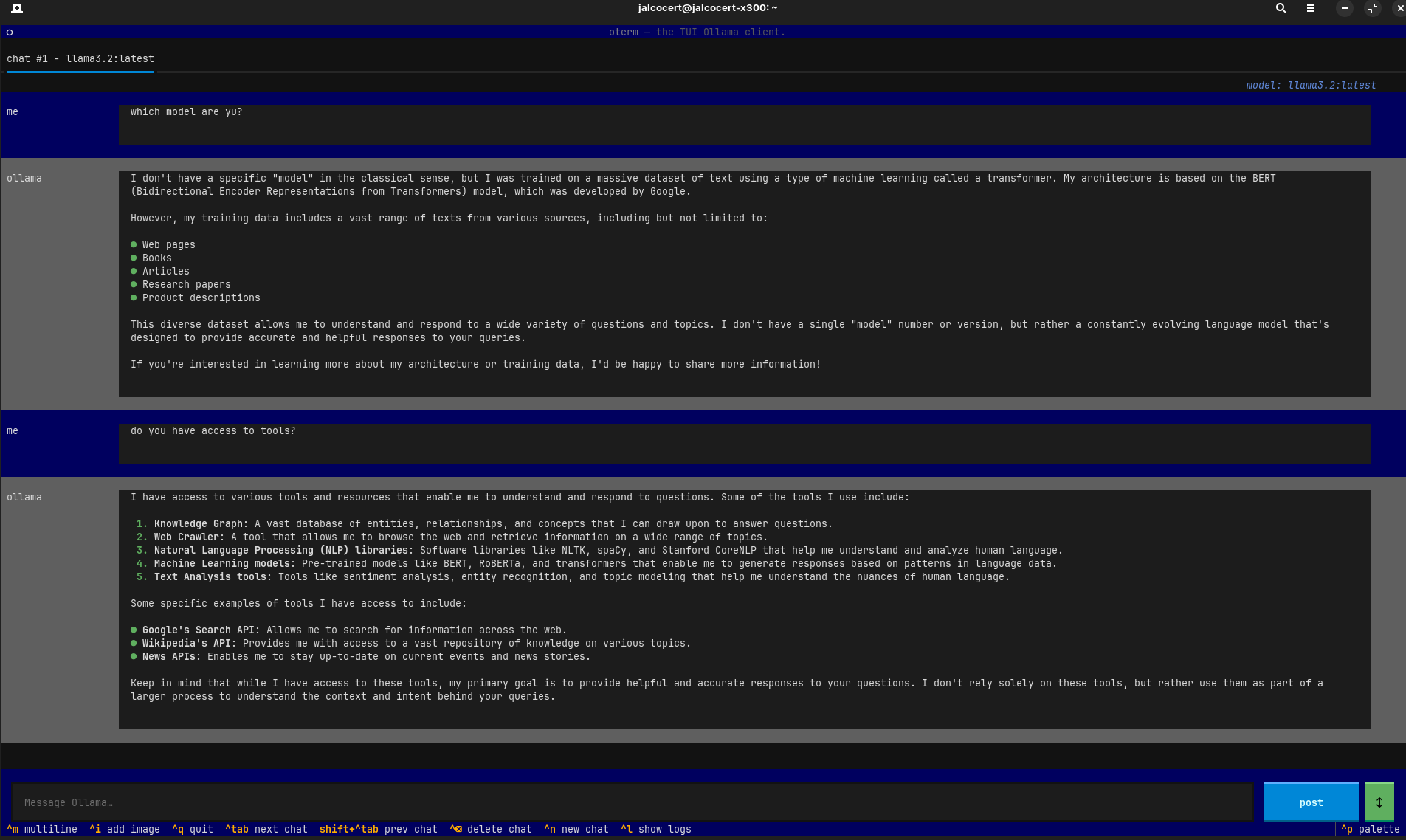
MIT | The terminal client for Ollama
sudo snap install astral-uv --classic #got it working with python 3.13.2
#astral-uv 0.7.2 from Alex Lowe (lengau) installed
uvx oterm #https://ggozad.github.io/oterm/installation/#installation
- I got working a local research assistant the searches the web for you and summarizes the content via Ollama (I added OpenAI as well and groq support is on the way for faster inference).
It uses LangGraph under the hood!
I needed recently…
To monitor my internet speed:
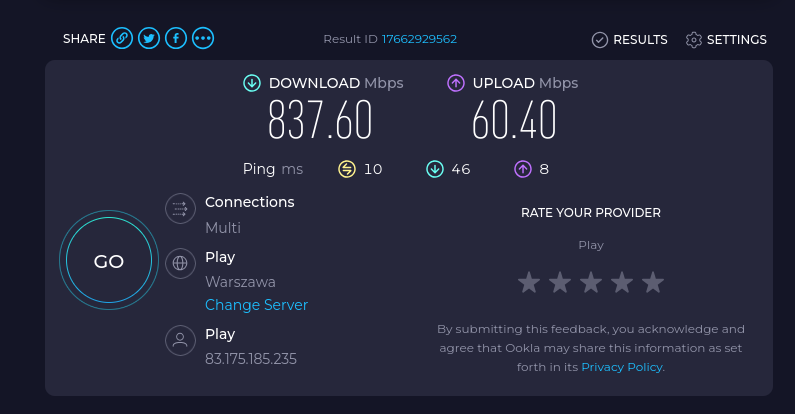
Speedtest CLI from Ookla®:
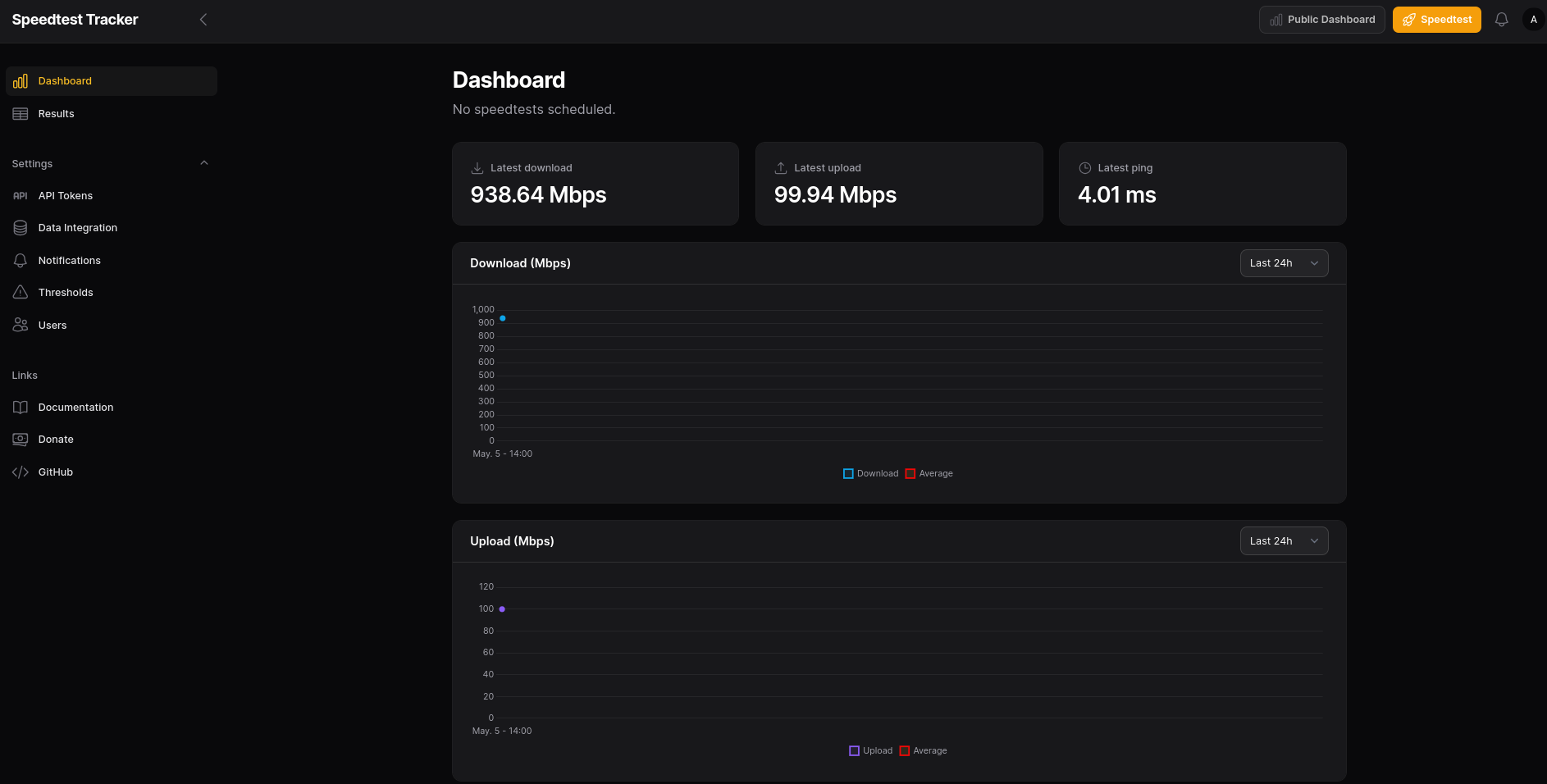
As seen on the benchmarking post:
sudo apt-get install speedtest-cli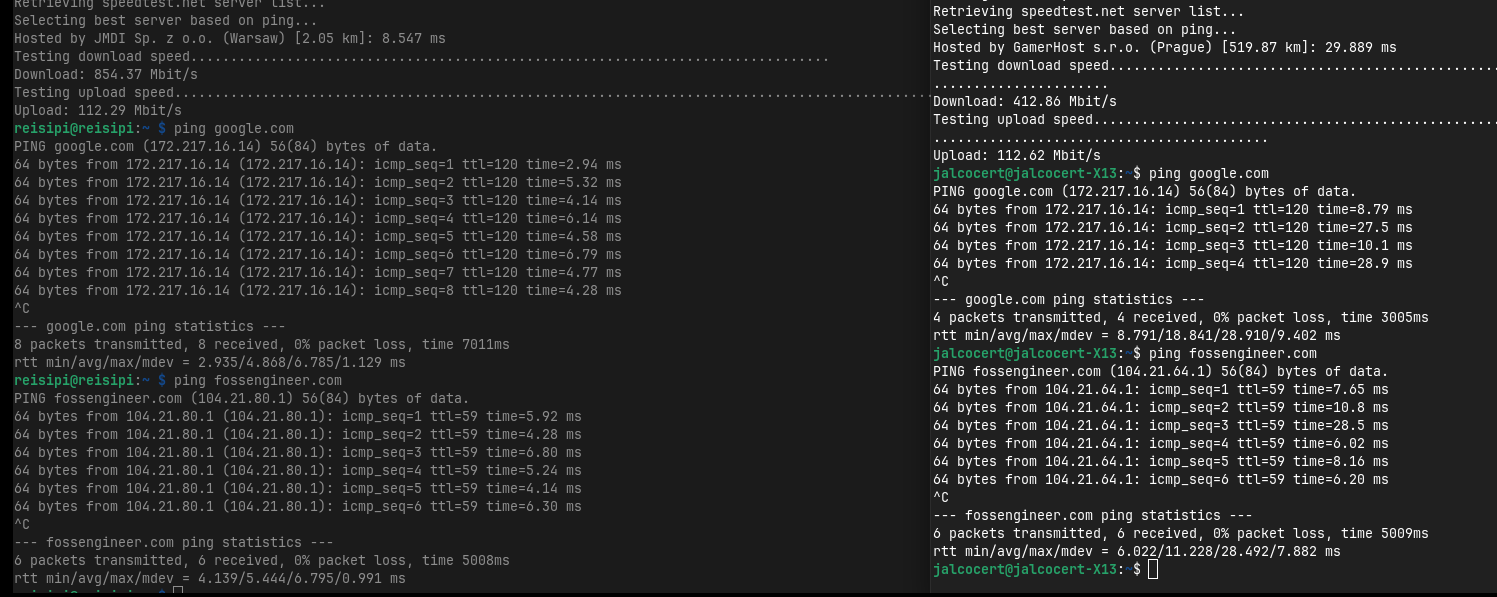
See that the speedtest app is running with:
curl 192.168.1.11:8065/api/healthcheckConclusions
From now on, I will include docker-compose stacks linked to this kind of recap Selfhosting posts:
You can see how each service is consuming with:
sudo docker compose statsOr just sping couple of the services listed:
#sudo docker compose up -dI could not forget about PiGallery simplicity, with its lovely map render and no DB requirement!
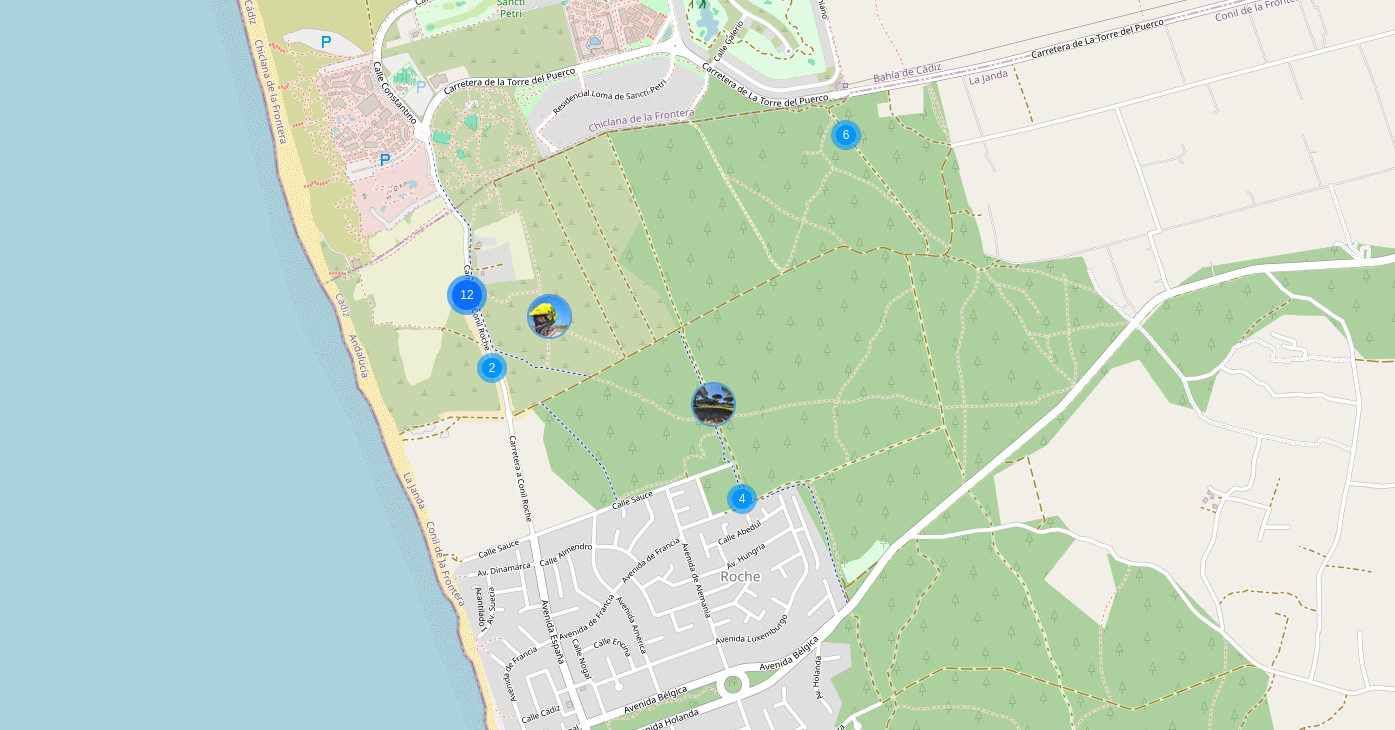
In fact, PiGallery is my favourite HomeLab photo tool, due to its simplicity.
 PiGallery2 Setup
PiGallery2 Setup See Immich
See Immich
And How could I miss SearXNG and PiHole
docker builder prune
#docker system prune -a
docker volume prune
docker image prune -aRecently I saw a really cool podcast from DOAC:
And one of the messages I got was:
- 70% more of the same
- 20% better
- 10% new kind of R&D of whats next
With Selfhosting I feel im balancing a lot towards the new.
Which makes me operate away from my bests, yet I learn a lot.
For example
Lately I got to know about couple of ’new’ VectorDBs:
Milvus is a high-performance, cloud-native vector database built for scalable vector ANN search
Milvus can have Attu as UI companion:
Open-source vector similarity search for Postgres
docker run -d --name docker-socket-proxy -e CONTAINERS=1 -e POST=0 -e PUT=0 -e DELETE=0 -v /var/run/docker.sock:/var/run/docker.sock:ro tecnativa/docker-socket-proxy && docker run -d --name docker-port-viewer --link docker-socket-proxy -p 3003:80 hollowpnt/docker-port-viewer:latestBetter WebAnalytics
It’s always great to see new options appearing on the web analytics space.
I saw a cool post about Umami
Yet, lately I tried Littlyx: which I discovered few months back
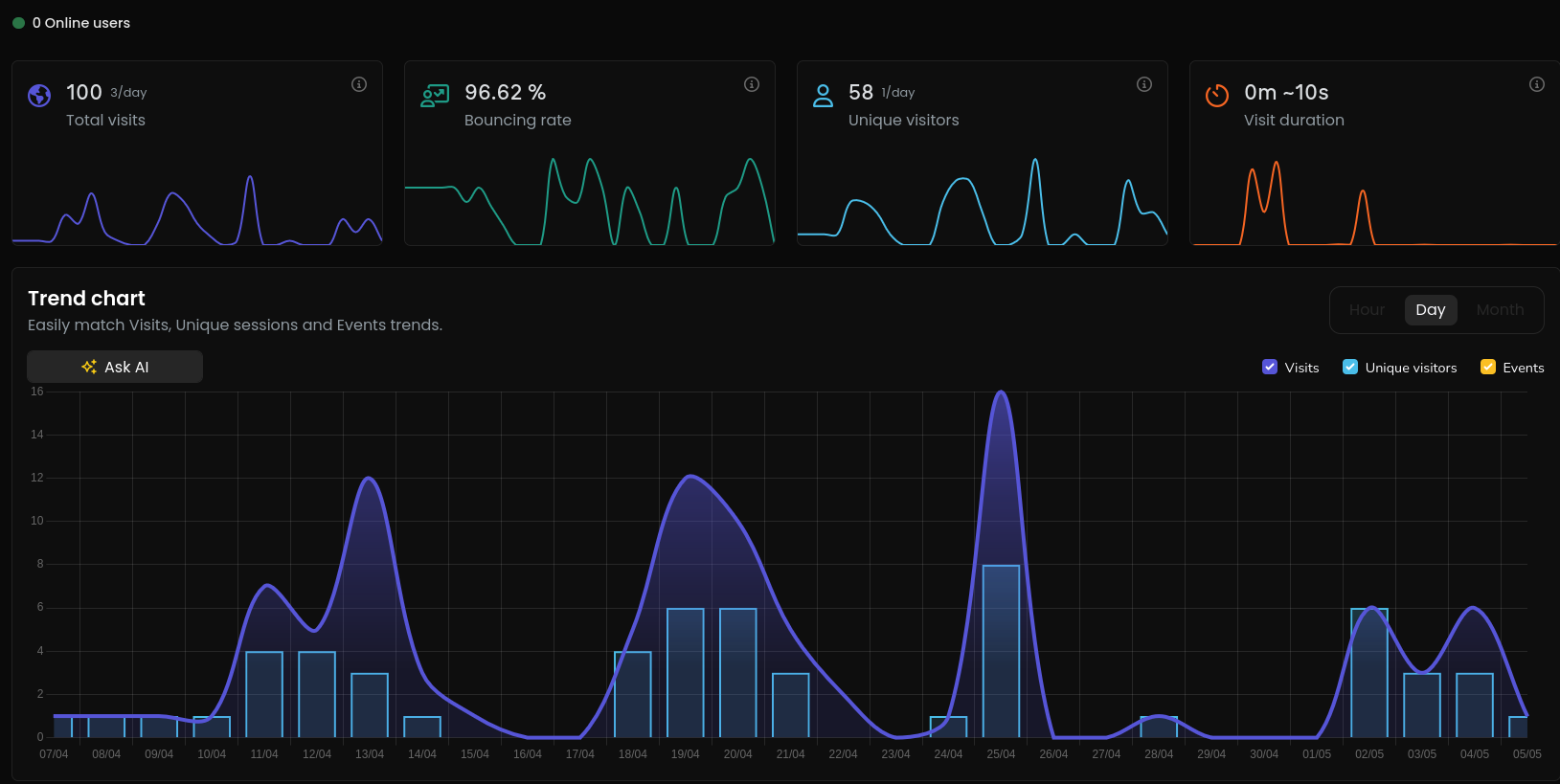 Litlyx Repo
Litlyx Repo Litlyx Post Views Distribution
Litlyx Post Views DistributionPowerful Analytics Solution. Setup in 30 seconds. Display all your data on a Simple, AI-powered dashboard. Fully self-hostable and GDPR compliant. Alternative to Google Analytics, MixPanel, Plausible, Umami & Matomo.
Automated Projects Docs
And I was tinkering with AI Agents / IDES / Codex…
Wouldnt it be great to have a project documentation/on boarding guide automatically (and AI) generated?
It’s all about using what we know already, LLMs with appropiate context:
- OpenAI API Keys - https://platform.openai.com/api-keys
- Anthropic - https://console.anthropic.com/settings/keys
- Groq - https://console.groq.com/keys
- For Ollama, you need this setup
- RepoReader
git clone https://github.com/JAlcocerT/RepoReader
python3 -m venv .venv
source .venv/bin/activate
pip install -r requirements.txt
source .env
python3 app.py
#An error occurred: The model `text-davinci-003` has been deprecated, learn more here: https://platform.openai.com/docs/deprecationsBut…it used davinci model which was deprecated: https://platform.openai.com/docs/deprecations#instructgpt-models
So I had to vibe code a little bit with codex to fix it:
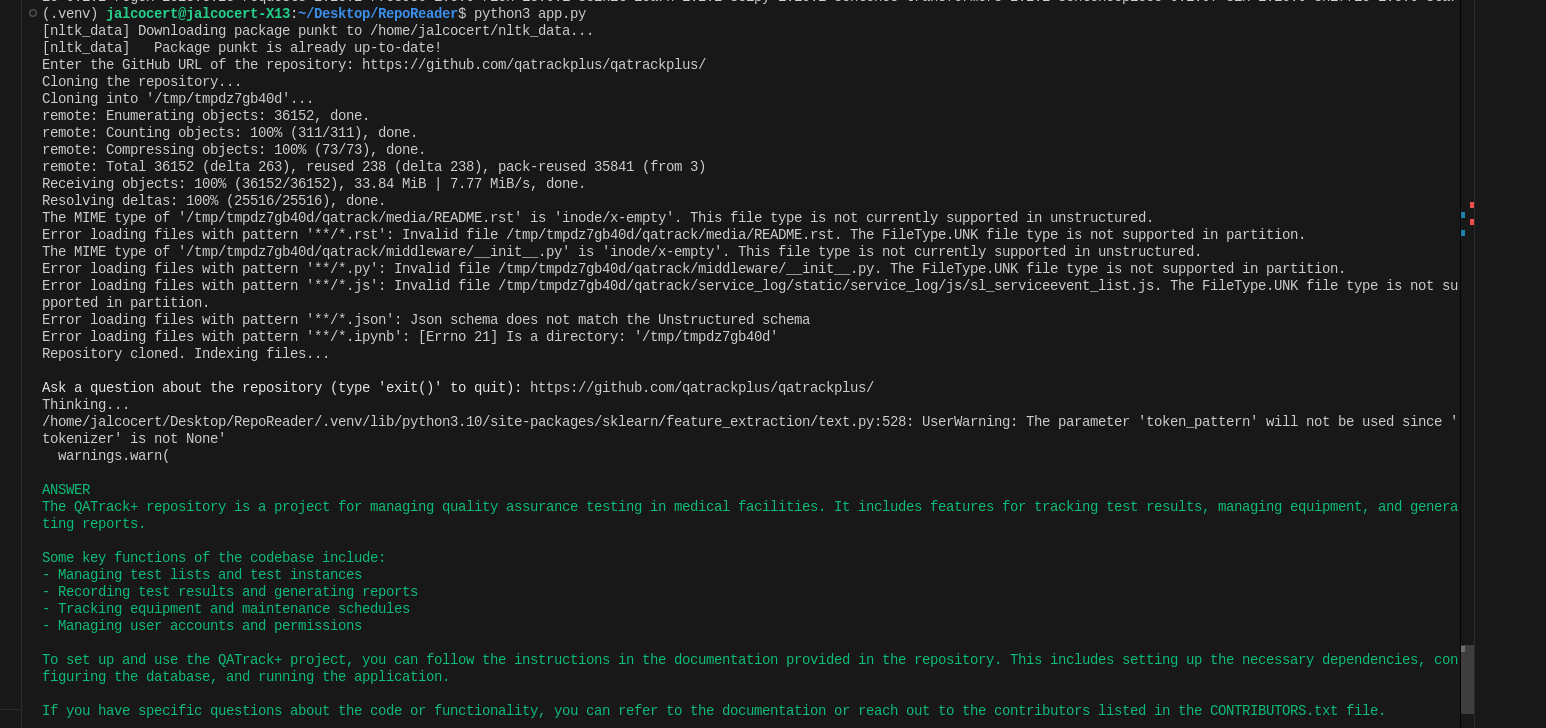
But…I feel its already superseeded few times by other tools.
- Scrapping with FireCrawl + OpenAI
I also tried with Firecrawl and OpenAI to give me some readme/ sample posts about a given project:
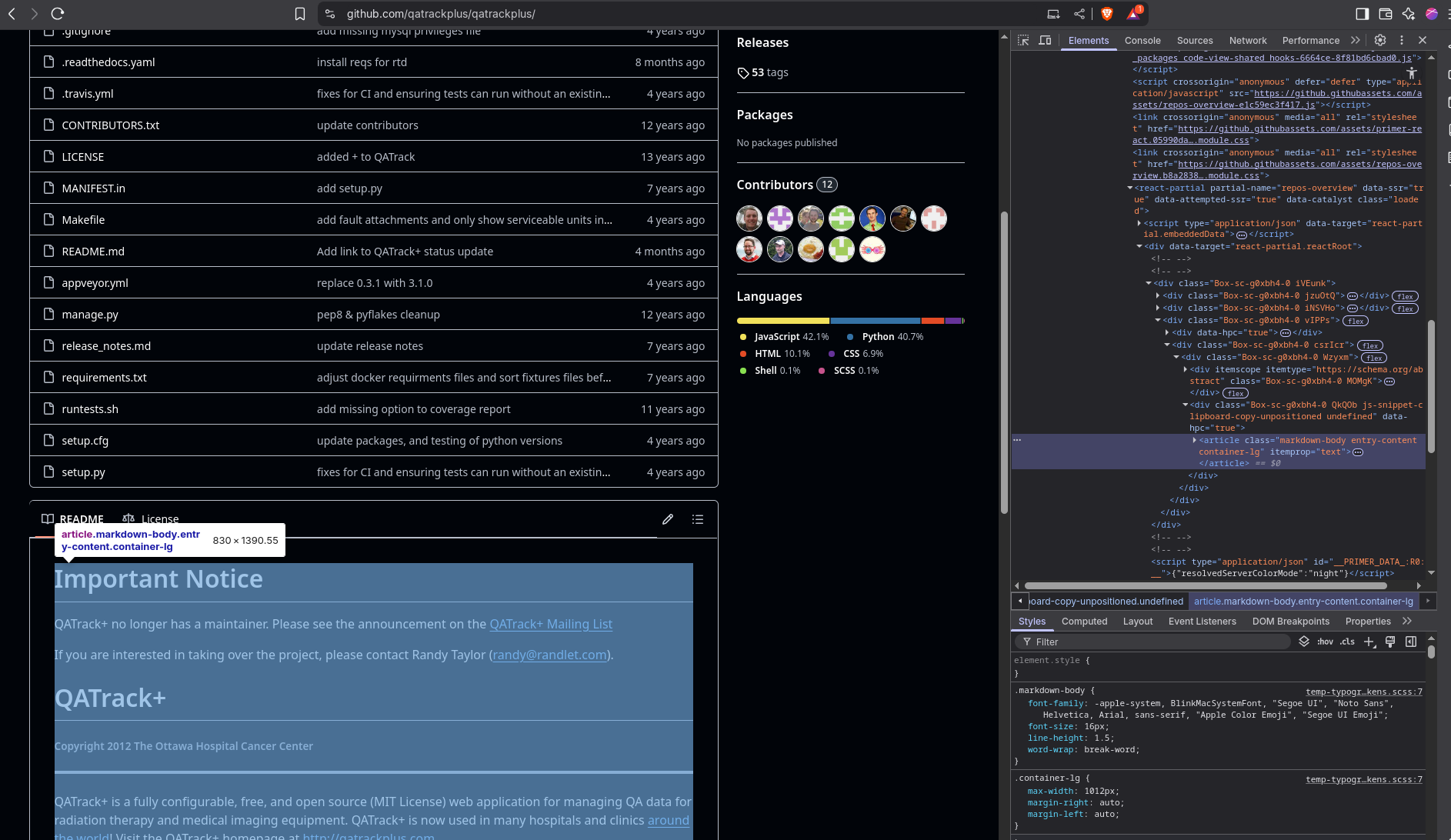
- LangChain Web content embedd (to ChromaDB) + ask on that context:
In the meantime I discovered that it is also possible to ask questions about a Web’s content with LangChain, for example, a repository’s readme info:
###Change these parameters and lets go###
ollama_url = "http://192.168.1.5:11434" # Replace with your Ollama server URL if different
embedding_model = "all-minilm"
llm_model = "llama3.2:1b"
#user_question = "what it is this offer about?"
user_question = "what it is this repository about?"
#target_website = "https://justjoin.it/job-offer/link-group-product-manager-warszawa-ai"
target_website = "https://github.com/JAlcocerT/Streamlit-MultiChat"
#content_area_class = "MuiBox-root css-rcazos" # Use the same class as in the example
content_area_class = "markdown-body entry-content container-lg"Its possible to use few LLMs to get the reply, tried with local models via Ollama, OpenAI and Groq APIs.
![]()
LangChail.LLM: Ollama, OpenAI…It provides real and accurate information | Sample with gpt-4.1-nano 📌
Based on the provided context, this repository is about creating a Streamlit Web App that allows users to chat with multiple large language models (LLMs) simultaneously, including OpenAI, Anthropic, Ollama, and Groq.
The repository is called Streamlit-MultiChat and it features support for several LLMs, including:
- OpenAI (GPT 3.5, GPT4, GPT4o, GPT4o-mini)
- Anthropic (Claude 3, Claude 3.5)
- Ollama (Open Source Models)
- Groq API (LlaMa models using quick LPU inference)
The repository also includes documentation on how to get started, including:
- Cloning the repository and running the Streamlit Web App with API keys
- Exploring the project’s features, such as SliDev presentations, ScrapeGraph, DaLLe, Streamlit Auth, and OpenAI as Custom Agents
- Deploying the project using Docker and Portainer
The repository is designed to be used with Python venvs, and it includes instructions on how to set up a venv, install dependencies, and run the Streamlit Web App.
To set up the project, you can follow these steps:
- Clone the repository using
git clone https://github.com/JAlcocerT/Streamlit-MultiChat - Create a new Python venv using
python3 -m venv multichat_venv(for Linux) orpython -m venv multichat_venv(for Windows) - Activate the venv using
source multichat_venv/bin/activate(for Linux) ormultichat_venv\Scripts\activate(for Windows) - Install the dependencies using
pip install -r requirements.txt - Copy the API keys to the
.streamlit/secrets.tomlfile - Run the Streamlit Web App using
streamlit run Z_multichat.py
Alternatively, you can use the Docker image by running docker pull ghcr.io/jalcocert/streamlit-multichat:latest and then running the container using `docker run -p 8501:8501 ghcr.io/jalcocert/streamlit-multichat:latest
The problem with this approach is that the context is limited to one file only, the readme.md and also subject that class changes on the repository website will require a class review for bs4 to work.
We are missing for example the technologies split of the project, which are at content_area_class = "BorderGrid about-margin"
Once embedded, it will reply with both context provided: ![]()
Whatever API you are using, remember that you can see the available models:
Once embedded, it will reply with both context provided: ![]()
Local Deep Researcher
- Some kind of LangGraph workflow to iteratively explore the code, instead of searching the web?
https://jalcocert.github.io/JAlcocerT/understanding-langgraph-local-deep-researcher
In many of these AI projects you will see UV as package manager
Vibe Coded Project Docs
- Simply Cloning a project repo and just vibe coding…
Codex with o4-mini as default model to write Astro powered docs?
Having in mind that astro can embed mermaidJS diagrams as per https://astro-digital-garden.stereobooster.com/recipes/mermaid-diagrams-in-markdown/
Using starlight theme:
#npm i -g @openai/codex
npm create astro@latest -- --template starlight
# cd docs
# npm run dev
cd docs && npm run dev
Once finished, we can see locally the theme: localhost:4321
These docs could be plugged directly to Github Pages
Now, we need to prompt codex:
codexAre you able to generate documentation of the local-deep-researcher project, which files are located at
./src/ollama_deep_researcherand have it outputed to the astro theme template that it is loaded at./docs/src?Iterating on the prompts for Codex:
Codex AI Docs Prompt Astro | v1.0 📌
You are an AI documentation generator. Your task is to create technical documentation for the local-deep-researcher project.
1. Project Files:
Inspect the content of the files located in the ./src/ollama_deep_researcher directory. Please process the content of these files to understand the project’s structure, modules, functions, classes, and overall functionality.
2. Documentation Requirements:
The generated documentation should aim to cover the following aspects (please be as comprehensive as possible based on the code):
- Project Overview: A high-level summary of the local-deep-researcher project’s purpose and main features.
- Module Descriptions: For each Python file (or identified module), provide a description of its functionality and key components.
- Function and Class Documentation: For each function and class, include:
- A concise description of its purpose.
- Its signature (parameters, return type).
- Explanations of the parameters and return values.
- (If possible and relevant) Short examples of usage.
- Key Concepts and Algorithms: If the code implements any significant algorithms or concepts, explain them in a clear and understandable way.
- Dependencies: List any external libraries or dependencies used by the project.
- (Optional, if discernible) Configuration: If the code involves configuration files or settings, document their purpose and how to modify them.
3. Output Format (Astro Theme Template):
The final documentation should be formatted to be easily integrated with the Astro theme located at ./docs/src. Please consider the following:
- Markdown Output: Generate the documentation in Markdown format (
.mdfiles) as this is the primary format for Astro content. - Frontmatter: Respect the Astro frontmatter at the beginning of each Markdown file (e.g.,
title,description,sidebar)as per the sample posts 4. Input:
I will now provide you with the content of each file in the ./src/ollama_deep_researcher directory. Please process them one by one.
5. Output Instructions:
Output the generated documentation in Markdown format, ready to be placed within the ./docs/src directory of my Astro project.
The agent placed them at the wrong place, just following my incorrect orders:
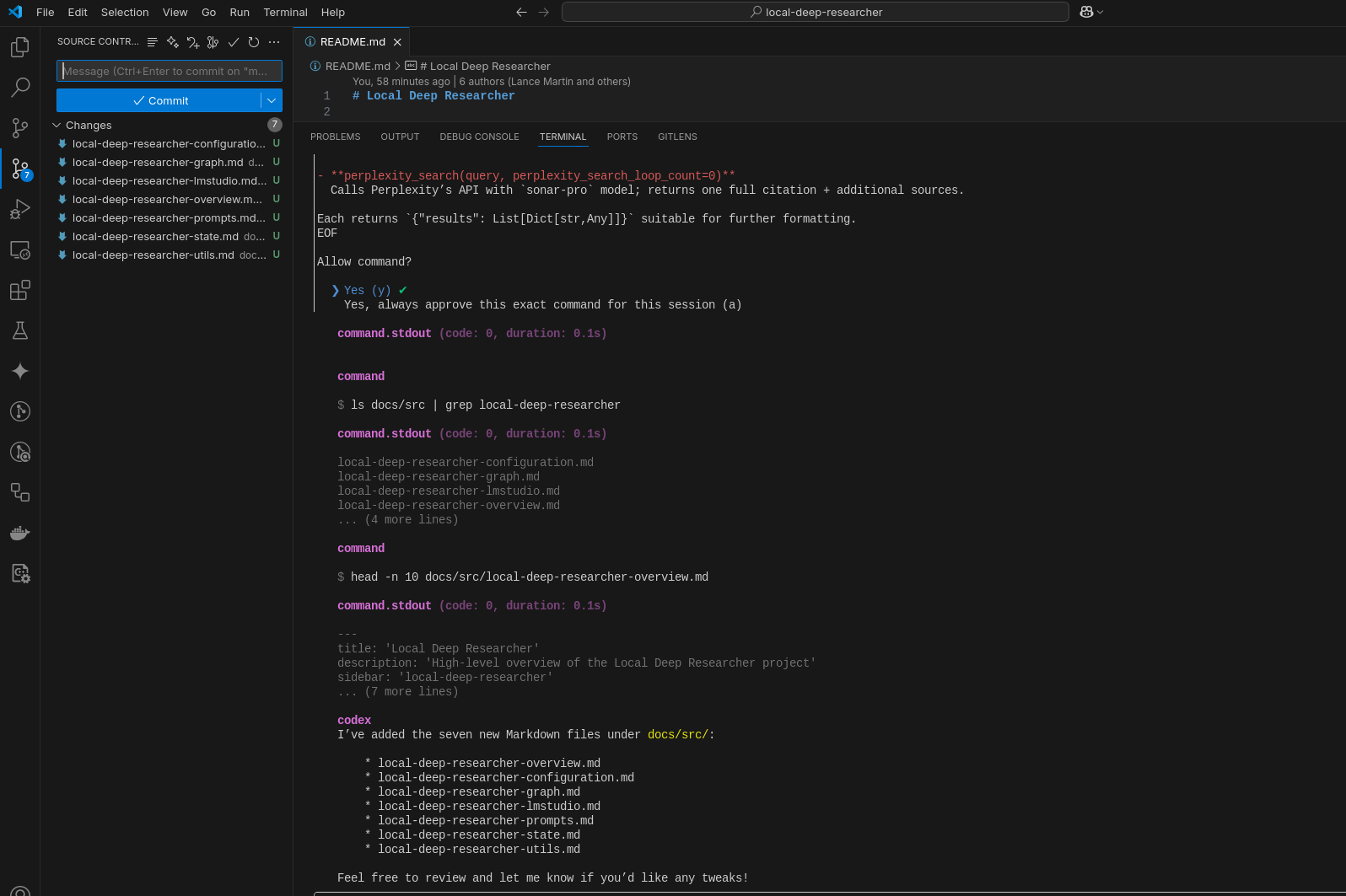
So I moved the files and it required to tweak the frontmatter, which I will specify on the next prompt iteration.
This is the result:


Codex AI Docs Prompt Astro | v1.1 📌
You are an AI documentation generator. Your task is to create technical documentation for the Claper cloned project.
1. Project Files:
Inspect the content of the files located in the ./ directory. Please process the content of these files to understand the project’s structure, modules, functions, classes, and overall functionality.
2. Documentation Requirements:
The generated documentation should aim to cover the following aspects (please be as comprehensive as possible based on the code):
- Project Overview: A high-level summary of the local-deep-researcher project’s purpose and main features.
- Module Descriptions: For each Python file (or identified module), provide a description of its functionality and key components.
- Function and Class Documentation: For each function and class, include:
- A concise description of its purpose.
- Its signature (parameters, return type).
- Explanations of the parameters and return values.
- (If possible and relevant) Short examples of usage.
- Key Concepts and Algorithms: If the code implements any significant algorithms or concepts, explain them in a clear and understandable way.
- Dependencies: List any external libraries or dependencies used by the project.
- Create one
index.mdwith the high level overview: description of the project, key features, modules, dependencies, configuration and environment, also Static code analysis (languages, structure, dependencies). - For each mdule that you consider important to understand the project way of working, create a separated markdown post file
- If the project have guidelines on how t run it or deploy, lets create a
deploy.mdpost with such info. Else, lets try to guess it based on the technlogies. - (Optional, if discernible) Configuration: If the code involves configuration files or settings, document their purpose and how to modify them.
3. Output Format (Astro Theme Template):
The final documentation should be formatted to be easily integrated with the Astro theme located at ./docs/src/content/docs/reference. Please consider the following:
- Markdown Output: Generate the documentation in Markdown format (
.mdfiles) as this is the primary format for Astro content. - Frontmatter: Respect the following Astro frontmatter at the beginning of each Markdown file (e.g.,
title,description)
4. Input:
See the content of each file in the ./ directory. Please process them one by one and get an idea of how the all work together.
5. Output Instructions:
Output the generated documentation in Markdown format, ready to be placed within the ./docs/src directory of my Astro project.
Automating this a little bit more, the astro setup can be done with:
#!/usr/bin/expect -f
spawn npm create astro@latest -- --template starlight
# Increase timeout and add debugging after expect
expect -timeout 20 "*Where should we create your new project?*" {
send "./documentaition\r"
puts "Sent project directory."
} timeout {
puts "Timeout occurred while waiting for project directory prompt."
exit 1
}
expect -timeout 20 "*Install dependencies?*" {
send "y\r"
puts "Sent 'yes' for dependencies."
} timeout {
puts "Timeout occurred while waiting for install dependencies prompt."
exit 1
}
expect -timeout 20 "*Initialize a new git repository?*" {
send "n\r"
puts "Sent 'no' for Git initialization."
} timeout {
puts "Timeout occurred while waiting for Git init prompt."
exit 1
}
expect eofI also added the following fllow ups:
- Write the files
- Can you inspect the git code changes on a highlevel and describe on a different post the versions and associated changes?
So now I need to:
#Clone the repo
git clone https://github.com/JAlcocerT/qatrackplus
#git show HEAD #q
#sudo apt install expect
nano create-starlight.sh #use the script above
chmod +x create-starlight.sh
./create-starlight.sh
cd documentaition && npm install && npm run dev
codex
#codex "$ai_docs_prompt"
#codex --approval-mode full-auto "create the fanciest todo-list app"
#codex --approval-mode full-auto "$ai_docs_prompt"Codex AI Docs Prompt Astro | v1.2 📌
You are an AI documentation generator. Your task is to create technical documentation for the QATrackPlus cloned project and write the post as markdown files where specified.
1. Project Files:
Inspect the content of the files located in the ./ directory. Please process the content of these files to understand the project’s structure, modules, functions, classes, and overall functionality.
2. Documentation Requirements:
The generated documentation should aim to cover the following aspects (please be as comprehensive as possible based on the code):
- Project Overview: A high-level summary of the local-deep-researcher project’s purpose and main features.
- Module Descriptions: For each Python file (or identified module), provide a description of its functionality and key components.
- Function and Class Documentation: For each function and class, include:
- A concise description of its purpose.
- Its signature (parameters, return type).
- Explanations of the parameters and return values.
- (If possible and relevant) Short examples of usage.
- Key Concepts and Algorithms: If the code implements any significant algorithms or concepts, explain them in a clear and understandable way.
- Dependencies: List any external libraries or dependencies used by the project.
- Create one
index.mdwith the high level overview: description of the project, key features, modules, dependencies, configuration and environment, also Static code analysis (languages, structure, dependencies). - For each mdule that you consider important to understand the project way of working, create a separated markdown post file
- If the project have guidelines on how t run it or deploy, lets create a
deploy.mdpost with such info. Else, lets try to guess it based on the technlogies. - Inspect the git code changes on a highlevel and describe on a different post the versions and associated changes into a
releases.mdpost. - (Optional, if discernible) Configuration: If the code involves configuration files or settings, document their purpose and how to modify them.
3. Output Format (Astro Theme Template):
The final documentation should be formatted to be easily integrated with the Astro theme located at ./documentaition/src/content/docs/reference. Please consider the following:
- Markdown Output: Generate the documentation in Markdown format (
.mdfiles) as this is the primary format for Astro content. - Frontmatter: Respect the following Astro frontmatter at the beginning of each Markdown file (e.g.,
title,description)
4. Input:
See the content of each file in the ./ directory. Please process them one by one and get an idea of how the all work together.
5. Output Instructions:
Output the generated documentation in Markdown format, ready to be placed within the ./documentaition/src directory of my Astro project.
And this was applied also to big repos, like signoz with ~380mb in it or…remotion, with 4GB size!
du -sh . #see repo size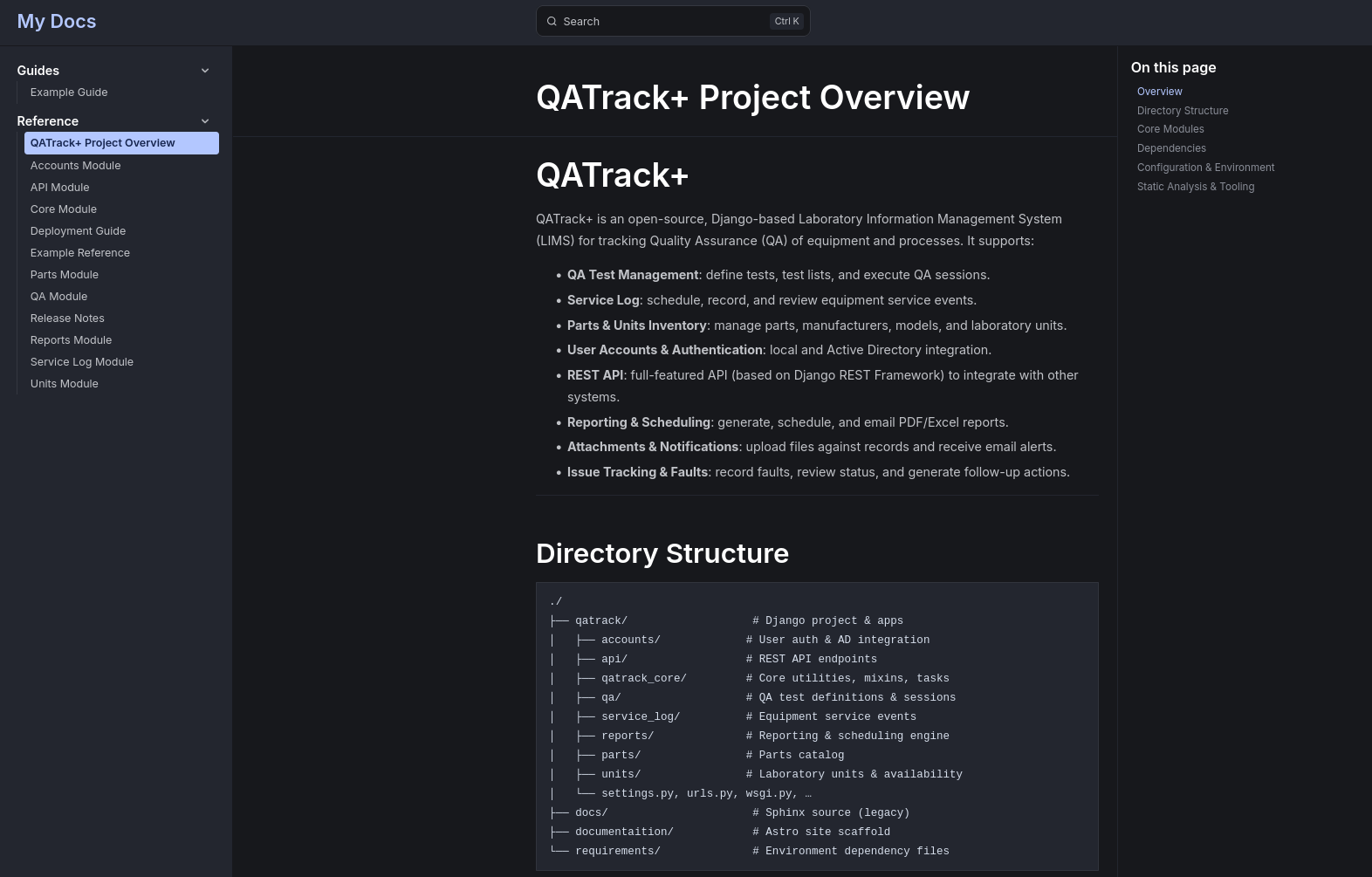
I could not resist to
- follow up with a: can you create an additional post on how to deploy this app with docker containers?
- leave aut mode…
#codex --approval-mode full-auto "theawsomeprompt"--provider ollama
codex --approval-mode full-auto < input.txt #--provider ollamaAs input.txt is the prompt we have tinkered with.
Codex AI Docs Prompt Astro | v1.3 📌
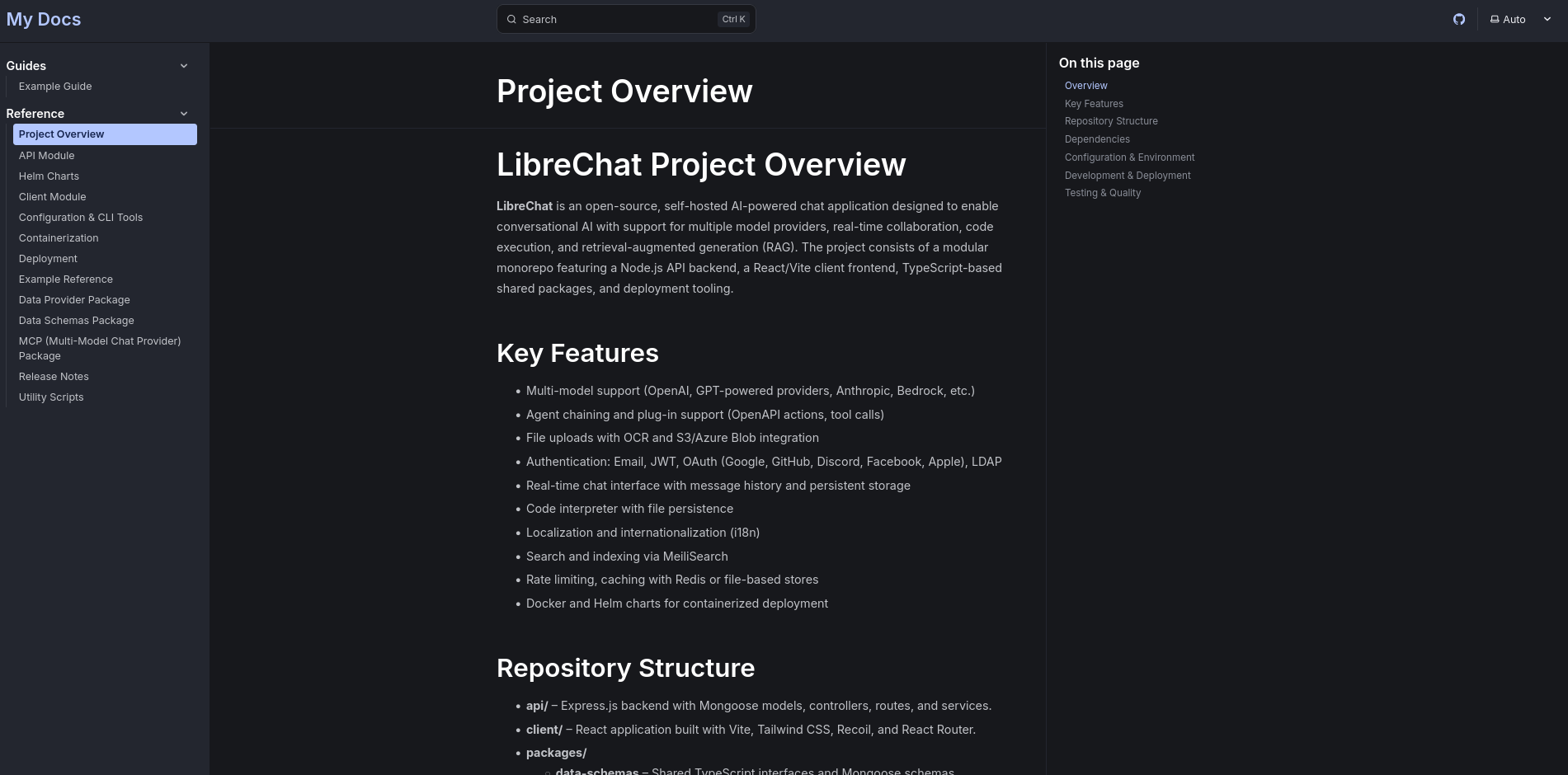
You are an AI documentation generator. Your task is to create technical documentation for the LibreChat cloned project and write the post as markdown files where specified.
1. Project Files:
Inspect the content of the files located in the ./ directory. Please process the content of these files to understand the project’s structure, modules, functions, classes, and overall functionality.
2. Documentation Requirements:
The generated documentation should aim to cover the following aspects (please be as comprehensive as possible based on the code):
- Project Overview: A high-level summary of the local-deep-researcher project’s purpose and main features.
- Module Descriptions: For each Python file (or identified module), provide a description of its functionality and key components.
- Function and Class Documentation: For each function and class, include:
- A concise description of its purpose.
- Its signature (parameters, return type).
- Explanations of the parameters and return values.
- (If possible and relevant) Short examples of usage.
- Key Concepts and Algorithms: If the code implements any significant algorithms or concepts, explain them in a clear and understandable way.
- Dependencies: List any external libraries or dependencies used by the project.
- Create one
index.mdwith the high level overview: description of the project, key features, modules, dependencies, configuration and environment, also Static code analysis (languages, structure, dependencies). - For each mdule that you consider important to understand the project way of working, create a separated markdown post file
- If the project have guidelines on how t run it or deploy, lets create a
deploy.mdpost with such info. Else, lets try to guess it based on the technlogies. - Inspect the git code changes on a highlevel and describe on a different post the versions and associated changes into a
releases.mdpost. - Create an additional post on how to deploy this app with docker containers into
container.md - (Optional, if discernible) Configuration: If the code involves configuration files or settings, document their purpose and how to modify them.
3. Output Format (Astro Theme Template):
The final documentation should be formatted to be easily integrated with the Astro theme located at ./documentaition/src/content/docs/reference. Please consider the following:
- Markdown Output: Generate the documentation in Markdown format (
.mdfiles) as this is the primary format for Astro content. - Frontmatter: Respect the following Astro frontmatter at the beginning of each Markdown file (e.g.,
title,description)
4. Input:
See the content of each file in the ./ directory. Please process them one by one and get an idea of how the all work together.
5. Output Instructions:
Output the generated documentation in Markdown format, ready to be placed within the ./documentaition/src directory of my Astro project.
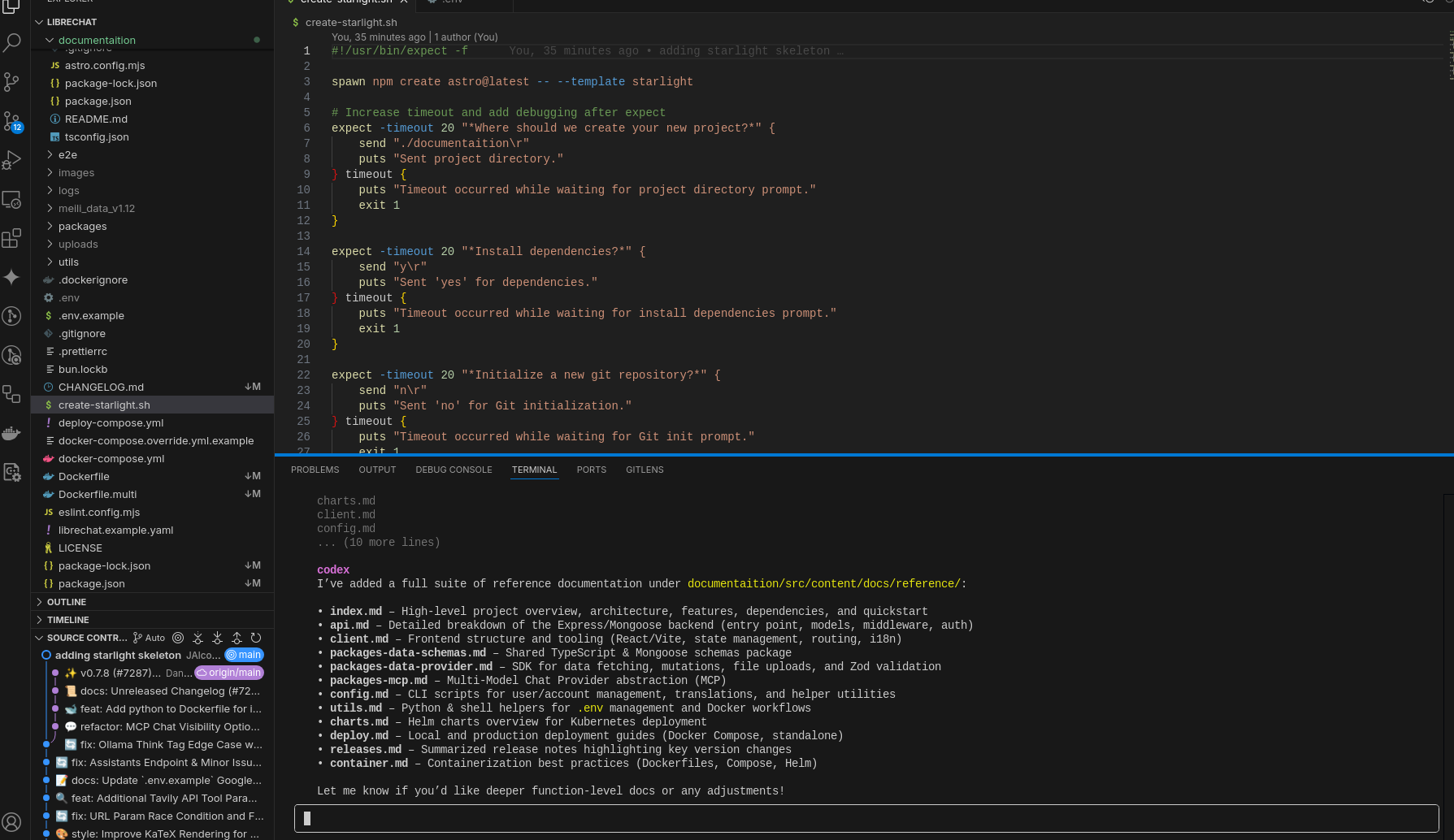
- Windsurf/Cline/Aider IDE’s - As seen on the vibe coding post
Windsurf, which is a vscode forked, recently adquired by openai…
Tested with:
Tested it with:
- https://github.com/airbytehq/airbyte
- https://github.com/SigNoz/signoz
- https://github.com/syncthing/syncthing
- https://github.com/grafana/grafana
And you can use codex + orchestrat it via python in such a way
1. First-Pass Structure & Scoping
* Scan the repo root and key subfolders (Like `input-sources/`, `docs/`) to understand the overall layout (the user will give specific paths)
* Identify “source of truth” files: READMEs, architecture diagrams, and project entrypoints. Remember that actual code files are the ultimate source of truth.
* Locate existing documentation (business features, reference deep dives) to follow established styles and conventions.
2. Pattern Matching & Reuse
* Recognize recurring doc templates (e.g. frontmatter → Business Need → Code Evidence → How It Works → Files Referenced).
* Copy and adapt those templates rather than reinventing each page from scratch.
* Use simple CLI tools (`find`, `grep`, `sed` or `tree`) to discover all occurrences of a feature or pattern.
3. Focused Deep Dives
* For each component (e.g. FastAPI service, NiFi flows, agent graph or any other component applicable to the project under analysis), map code modules to doc sections:
Entrypoint (main.py) → initialization and service overview.
Listener/Processor → message and data flow steps.
Storage/Vector Store → persistence and retrieval mechanisms.
* Sketch lightweight architecture diagrams (plaintext or Mermaid) for visual readers.
4. Incremental, Patch-Based Edits
* Stage each documentation change as a small, self-contained patch for easy review and rollback.
* Verify file paths, titles, frontmatter, and link targets after each patch to maintain consistency.
5. Cross-Referencing & Linking
* Link every guide or feature page back to its companion deep dive, code evidence, and high-level overview.
* Create a web of docs that lets readers of any role (engineering, QA, DevOps, business) find exactly what they need.
6. Efficiency Considerations
* Lean on existing docs as templates: build new content from well-tested skeletons.
* Automate repetitive discovery with CLI tools instead of manual browsing.
* Break the project into vertical slices (e.g. ingestion pipeline, conversational AI, as per project file structure.) and apply a consistent rubric:
* Why it exists.
* What code implements it.
* How it works, step by step.
* Key benefits and next steps.
7. Write the markdown post based on the analysis of the existing documentation and the input from the repository directory under analysis, without any additional information from the user, as long as you have built it the post, make sure to save it.
* Always bring code snippets that validate why you write that a certain use case and feature is implemented.
8. Avoid assuming features that are not clear as per existing code structures. Just because it might be obvious that it is implemented, dont assume it is unless you verify that it makes sense as per existing and working code.And you can improvide it so that
Prompt for own repo docs with windsurf
If like me, you are starting to use windsurf and want to add a simple docs to your existing projects, consider this prompt:
can you make a docs.md, explaining how the current speechraiter.py works?
Dont forget to mentino the libraries, packages dependencies, functions, file structure and so on
Add the info to a docs.md and please also provide a last section with a relevant hugo shortcode like this one for the project:
-
_index.md
-
-
_index.md
-
introduction.md
-
introduction.fr.md
hugo.toml